








Using Hazelcast in the Kappa architecture
- 1. Using Hazelcast as the Serving Layer in the Kappa Architecture Presented by Oliver Buckley-Salmon June 1st 2017 Twitter: @SalmonOliver Github: https://github.com/oliversalmon LinkedIn: Oliver Buckley-Salmon
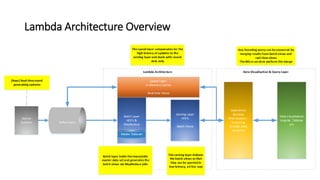
- 2. Introduction • Many Industries have a combined need to view and process big and fast data • Previously tools such as Hadoop allowed the processing of large data sets but at high latency and stream processing systems processed small amounts of data very fast • Recently new architectures have been suggested to combine both of these to provide a single solution for big and fast data, with a couple of the most well known below • Lambda Architecture • Nathan Marz came up with the term Lambda Architecture (LA) for a generic, scalable and fault-tolerant data processing architecture, based on his experience working on distributed data processing systems at Backtype and Twitter • The LA aims to satisfy the needs for a robust system that is fault-tolerant, both against hardware failures and human mistakes, being able to serve a wide range of workloads and use cases, and in which low-latency reads and updates are required • The resulting system should be linearly scalable, and it should scale out rather than up • Kappa Architecture • Kappa Architecture is a simplification of Lambda Architecture • A Kappa Architecture system is like a Lambda Architecture system with the batch processing system removed • To replace batch processing, data is simply fed through the streaming system quickly
- 4. Benefits & Challenges with Lambda Architecture Benefit Challenge Real-time view & analysis of latest data Synchronisation between Speed & Batch layers Support historical data queries & analytics Analytics only, not operational/transactional Horizontally scalable speed layer 2 separate sub systems for microservices to read from depending on life cycle Horizontally scalable batch layer Heavy focus on HDFS / Storage / format optimization Allows use of Hadoop ecosystem for batch processing & analytics Unpredictable latency of batch layer Fault tolerant
- 6. Benefits & Challenges with Kappa Architecture Benefit Challenge Real-time view & analysis of latest data Allowing serving layer to replay from Kafka on demand to support historical queries on demand Single view of data (serving layer only) Latency and reprocessing required for historical queries Horizontally scalable serving layer Analytics only, not operational/transactional Horizontally scalable distributed log layer (Kafka) Hard sell to convince management that Kafka log is the database! Horizontally Stream Processing layer Kafka log sizes Fault tolerant Doesn’t leverage Hadoop ecosystem for large scale analytics Support historical data queries & analytics through Kafka replays into Serving layer Allows the Stream Computation layer to do the heavy lifting Fewer moving parts than Lambda Architecture Simpler programming model – everything is a stream
- 7. Hazelcast in the Kappa Architecture
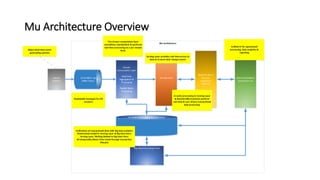
- 8. Introduction to Mu Architecture • Many Industries have a combined need to view and process big and fast data. The Lambda & Kappa architectures solve the Big & Fast data problem but only for analytics • Traditionally there would be two separate architectures, one for OLTP one for OLAP • Modern software allows us to combine the two into a single platform • No need for complex ETL or ELT • No delay for transactional data to be available for analytics • Real-time reactive microservices and transaction processing • Massively horizontally scalable • Cloud ready • By combining big data technology with in-memory technology the Mu architecture offers all of the above in an architecture that fits on one slide
- 10. Mu Architecture Demo – Work In Progress Follow progress or join it at https://github.com/oliversalmon/imcs-demo
- 11. Summary • Many Industries have a combined need to view and process big and fast data • Previously tools such as Hadoop allowed the processing of large data sets but at high latency and stream processing systems processed small amounts of data very fast • The Lambda & Kappa architectures allow real-time analytics • In memory computing technology such as Hazelcast IMDG & Hazelcast Jet, combined with big data technologies, allows us to process vast volumes of unbounded data fast • The Mu architecture takes the best of both of the Kappa & Lambda architectures to produce a combined real-time OLTP & OLAP solution