
















































Using unicode with php
- 1. USING UNICODE WITH PHP Translation, localization, and 100% less mojibake guaranteed or your users won’t come back!
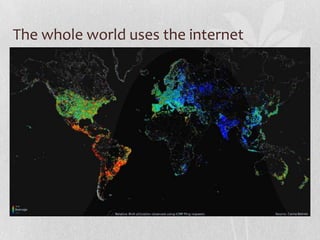
- 2. The whole world uses the internet
- 3. Why is internationalization important? Content language of websites Percentage of Internet users by language
- 4. Worse than no internationalization? Mojibake
- 5. Unicode is the solution! Well – kind of 1. Different encodings 2. OS’s have different default implementations 3. All software encodings have to match or convert Unicode Idea == simple Unicode Implementation == hard
- 6. Back to Basics WHAT IS UNICODE?
- 7. U·ni·code ˈ oniˈkōd yo͞ / Noun COMPUTING 1. an international encoding standard for use with different languages and scripts, by which each letter, digit, or symbol is assigned a unique numeric value that applies across different platforms and programs.
- 8. In the Beginning, there was ASCII
- 9. Code Pages In which things get really weird…
- 10. Representing characters differently ASCII Unicode One character to bits in memory Code point A -> 100 0001 A -> U+0041 Direct Abstract But how do we represent this in memory?
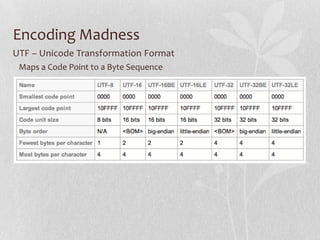
- 11. Encoding Madness UTF – Unicode Transformation Format Maps a Code Point to a Byte Sequence
- 12. What is a character? å U+212B ANGSTROM SIGN U+00C5 LATIN CAPITAL LETTER A WITH RING ABOVE U+0041 LATIN CAPITAL LETTER A + U+030A COMBINING RING ABOVE How long is the string? 1. In bytes? 2. In code units? 3. In code points? 4. In graphemes?
- 13. Crash course in Computer Memory Big endian systems - most significant bytes of a number in the upper left corner. Decreasing significance. Little endian systems – most significant bytes of a number in the lower right. Increasing significance.
- 14. Big Endian? Little Endian? You’re hurting my brain Hello -> U+0048 U+0065 U+006C U+006C U+006F 00 48 00 65 00 6C 00 6C 00 6F – Little Endian 48 00 65 00 6C 00 6C 00 6F 00 - Big Endian But.. It’s the same way to encode unicode… Now I have a headache!
- 15. UTF-8 to the rescue! Hello in ANSI -> 48 65 6C 6C 6 Hello in UTF8 -> 48 65 6C 6C 6
- 16. Moral of the story Unicode is a standard, not an implementation Text is never plain Every string has an encoding From a file From a db From an HTTP POST or GET (or PUT or file upload…) Even Binary is an encoding! No encoding? Start praying to the Mojibake gods… If you do web – use UTF-8
- 17. Mojibake on rye with swiss. WHY DO YOU NEED UNICODE?
- 19. Laruence
- 20. More than just UTF8 BEYOND STRINGS
- 21. I18n and L10N • Internationalization – adaptation of products for potential use virtually everywhere • Localization - addition of special features for use in a specific locale
- 22. Date and Time Formats 30 juin 2009 fr_FR 30.06.2009 de_DE Jun 30, 2009 en_US And don’t forget the time zones!
- 23. Currency and Numbers • 123 456 fr_FR • 345 987,246 fr_FR • 123.456 de_DE • 345.987,246 de_DE • 123,456 en_US • 345,987.246 en_US • French (France), Euro: 9 876 543,21 € • German (Germany), Euro: 9.876.543,21 € • English (United States), US Dollar: $9,876,543.21
- 24. Collation (Sorting) • The letters A-Z can be sorted in a different order than in English. For example, in Lithuanian, "y" is sorted between "i" and "k” • Combinations of letters can be treated as if they were one letter. For example, in traditional Spanish "ch" is treated as a single letter, and sorted between "c" and "d” • Accented letters can be treated as minor variants of the unaccented letter. For example, "é" can be treated equivalent to "e”. • Accented letters can be treated as distinct letters. For example, "Å" in Danish is treated as a separate letter that sorts just after "Z”.
- 25. String Translation • Translation is never one to one, especially when inserting items like numbers • Some languages have different grammars and formats for the strangest things • Usually translated strings are separated into “messages” and stored, then mapped depending on the locale • Large amounts of text need even more – different tables in a database, files in directories, or more
- 26. Layout and Design • Reading order • Right to left • Left to right • Top to bottom • Word order • Cultural taboos (human images, for example)
- 27. 3.5 extensions for triple the pain! HOW TO UNICODE WITH PHP
- 28. Upgrade to at least 5.3 • No, really, I’m entirely serious • If you’re not on 5.3 you’re not ready for unicode • At all • You have far bigger issues to deal with – like no security updates • (oh, and the extensions and apis you need either don’t exist or won’t work right)
- 29. Install the bare minimum • intl extension (bundled since PHP 5.3) • mb_string (if you need zend_multibyte support or on the fly conversion, but most anything else it can do intl does better) • iconv extension (optional but excellent for dealing with files) • pcre MUST have utf8 support (CHECK!)
- 30. PHP strings 101
- 31. C strings and encoding char - 1 byte (usually 8 bit) char * - a pointer to an array of chars stored in memory • Can handle Code Page encodings, although generally need special APIs for dealing with multibyte code pages • Usually null terminated… well unless it’s a binary string • Unix cleverly supports utf8 with apis • Windows … does not
- 32. Introducing a new type wchar_t – C90 standard (horribly ambiguous) • Windows set it at 16 – and defined A and W versions of everything • Unix set it at 32 C99 and C++11 do char16_t and char32_t to fix the craziness Non-portable and api support sketchy • Libraries to fix this exist • Few are cross-platform • Except for ICU – which just rocks
- 33. Why do we care? • PHP talks ONLY to ansi apis on windows • PHP functions assume ascii or binary encodings (except for a few special ones) • Although most functions are now marked “binary safe” and don’t flip out on null bytes within a string, some still assume a null terminated string • string handling functions treat strings as a sequence of single-byte characters.
- 34. Non-stupid PHP functionality (kinda) • utf8_encode (only ISO-8859-1 to UTF8) • utf8_decode (only UTF8 to ISO-8859-1) • html_ entity_ decode • htmlentities • htmlspecialchars_ decode • htmlspecialchars
- 35. C locales or how to make servers cry • Setlocale is Per process • I will repeat that – setlocale sets PER PROCESS • Locales are slightly different on different OS’s • Windows does not support utf8 properly
- 36. What setlocale will break •gettext extension • strtoupper • strtolower • number_format • money_format • ucfirst • ucwords • strftime
- 37. INTL to the rescue! • • • • • • • • • • • • • • Wrapper around the excellent ICU library Standardized locales, set default locale per script Number formatting Currency formatting Message formatting (replaces gettext) Calendars, dates, timezones and time Transliterator Spoofchecker Resource Bundles Convertors IDN support Graphemes Collation Iterators
- 38. Some intl caveats • New stuff is only in newer PHP versions • All strings in and out must be UTF-8 except for Uconvertor • Intl doesn’t yet support zend_multibyte • Intl doesn’t support HTTP input/output conversion • Intl doesn’t support function “overloading”
- 39. mb_string • enables zend_multibyte support • supports transparent http in and out encoding • provides some wrappers for functionality such as strtoupper (including overloading the php function version…)
- 40. Iconv • Primarily for charset conversion • output buffer handler • mime encoding functionality • conversion • some string helpers • • • • len substr strpos strrpos • stream filter stream_filter_append($fp, 'convert.iconv.ISO-2022-JP/EUC-JP');
- 41. Stay away from: • ctype (all of it) • filter extension with string functionality • • • • FILTER_VALIDATE_EMAIL FILTER_VALIDATE_URL FILTER_VALIDATE_REGEXP FILTER_SANITIZE_* • some string functionality • str_pad • wordwrap • others that might work only by looking at single bytes
- 42. What do you mean mysql is giving me garbage? BEYOND THE CODE
- 43. Browser Considerations • Set Content-type AND charset • use HTTP headers AND meta tags (not just meta) • use accept-charset on forms to make sure your data is coming in right • Javascript: string literals, regular expression literals and any code unit can also be expressed via a Unicode escape sequence uHHHH • Specify content-type AND charset headers for javascript!!
- 44. Databases Table/Schema encoding and connection • Mysql you need to set the charset right on the table AND • Set the charset right on the connection (NOT set names, it does not do enough) AND • Don’t use mysql – mysqli or pdo • postgresql - pg_set_client_encoding • oracle – passed in the connect • sqlite(3) – make sure it was compiled with unicode and intl extension is available • sqlsrv/pdo_sqlsrv – CharacterSet in options
- 45. Other gotchas • Plain text is not plain text, files will have encodings • Files will be loaded as binary if you add the b flag to fopen (here’s a hint, always use the b flag) • You can convert files on the fly with the iconv filter • You cannot use unicode file names with PHP and windows at all (no, not even utf8) – unless you find a 3 rd party php extension • Beware of sending anything but ascii to exec, proc_open and other command line calls
- 46. The best and worst in PHP apps CASE STUDIES
- 47. Applications • Wordpress • gettext (sigh) • Drupal • gettext files but NOT gettext api
- 48. Frameworks • ZF and ZF2 • http://framework.zend.com/manual/1.12/en/performance.localization.html • multiple adapters • “gettext” allows using fast .po files, but doesn’t use setlocale/gettext extension • Symfony 1 and 2 • http://symfony.com/doc/current/book/translation.html • multiple formats to hold translations • doesn’t use gettext
- 49. Resources • http://www.joelonsoftware.com/articles/Unicode.html • http://unicode.org • http://www.slideshare.net/andreizm/the-good-the-bad-andthe-ugly-what-happened-to-unicode-and-php-6 • http://php.net • http://www.2ality.com/2013/09/javascript-unicode.html • http://htmlpurifier.org/docs/enduser-utf8.html
- 50. My Little Project • Get everything needed into intl from mb_string and iconv so you need only 1 solution • • • • • stream filter from iconv output handler from iconv zend_multibyte support from mb_string http in and output conversion from mb_string Some simplified apis to make “overloading” doable
- 51. Contact • [email protected] • @auroraeosrose • http://emsmith.net • http://github.com/auroraeosrose • Freenode • #phpwomen • #phpmentoring • #php-gtk
Editor's Notes
- #2: Your application is great - and popular. You have translation efforts underway, everything is going well - and wait a minute, what's the report of strange question mark characters all over the page? Unicode is pain. UTF-32, UTF-16, UTF-8 and then something else is thrown in the mix ... Multibyte and codepoints, it all sounds like greek. But it doesn't have to be so scary. PHP support for Unicode has been improving, even without native unicode string support. Learn the basics of unicode is and how it works, why you would add support for it in your application, how to deal with issues, and the pain points of implementation.
- #3: World map of 24 hour relative average utilization of IPv4 addresses observed using ICMP ping requests as part of the Internet Census of 2012 (Carna Botnet), June - October 2012.[12] Key: from red (high), to yellow, green (average), light blue, and dark blue (low).The Carna Botnet was a botnet of 420,000 devices created by an anonymous hacker to measure the extent of the Internet in what the creator called the “Internet Census of 2012”.The data was collected by infiltrating Internet devices, especially routers, that used a default password or no password at all. It was named after Cardea, the roman goddess associated with door hinges.[1][2]It was compiled into a gif portrait to display Internet use around the world over the course of 24 hours. The data gathered included only the IPv4 address space and not the IPv6 address space.[3][4]The Carna Botnet creator believes that with a growing number of IPv6 hosts on the Internet, 2012 may have been the last time a census like this was possible.[5]
- #4: The number of non-English pages is rapidly expanding. The use of English online increased by around 281% from 2001 to 2011, however this is far less than Spanish (743%), Chinese (1,277%), Russian (1,826%) or Arabic (2,501%) over the same period.So there are More people using the internet every yearMore people whose native language is NOT english using the internetMany sites on the internet not in available in people’s native language
- #5: Mojibake (文字化け?) (IPA: [mod͡ʑibake]; lit. "character transformation"), from the Japanese 文字 (moji) "character" + 化け (bake) "transform", is the presentation of incorrect, unreadable characters when software fails to render text correctly according to its associated character encoding.
- #6: Computers store data as numbers, even textual data. An encoding system, such as ASCII, assigns a number to each letter, number or character. Operating systems include programs and fonts which convert these numbers to letters visible on the screen and computer monitor.Unicode, also known as UTF-8 or the "Universal Alphabet" is a an ordered set of over a million characters covering the majority of writing systems in the world. Unlike older systems, Unicode allows multiple writing systems to co-exist in one data file. Systems which recognize Unicode can consistently read and process data from many languages.
- #7: What is unicodeHow is unicode implementedWhat are the available types of unicode and why utf8 is your only choiceSimply supporting uft8 strings does not make your app magically workLocalization, rtl layouts and other headacheshttp://www.joelonsoftware.com/articles/Unicode.html
- #8: Unicode provides a unique number for every character, no matter what the platform, no matter what the program, no matter what the languageSO what does this mean in English? Well first let’s take a crash course on the basics of unicode that every developer should know
- #9: The only characters that mattered were good old unaccented English letters, and we had a code for them called ASCIIrepresent every character using a number between 32 and 127This could conveniently be stored in 7 bits. Most computers in those days were using 8-bit bytes, so not only could you store every possible ASCII character, but you had a whole bit to spare, which, if you were wicked, you could use for your own devious purposes Codes below 32 were called were used for control characters, like 7 which made your computer beepBecause bytes have room for up to eight bits, lots of people got to thinking, "gosh, we can use the codes 128-255 for our own purposes.Unfortunately they all had the SAME idea at the same time…
- #10: Eventually this OEM free-for-all got codified in the ANSI standard. In the ANSI standard, everybody agreed on what to do below 128, which was pretty much the same as ASCII, but there were lots of different ways to handle the characters from 128 and on up, depending on where you lived. These different systems were called code pages.Meanwhile, in Asia, even more crazy things were going on to take into account the fact that Asian alphabets have thousands of letters, which were never going to fit into 8 bits. This was usually solved by the messy system called DBCS, the "double byte character set" in which some letters were stored in one byte and others took two. It was easy to move forward in a string, but dang near impossible to move backwards.
- #11: Needless to say this did NOT work well – or at allWhat if you needed chinese and cyrrilic in the same documented and needed to move backward over a string?Yeah, well then you were screwedSo unicode came along to try to fix thisUnicode is a STANDARD – and IDEA – with different implementationsIn Unicode, a letter maps to something called a code point which is still just a theoretical concept. How that code point is represented in memory or on disk is another matter ….Every platonic letter in every alphabet is assigned a magic number by the Unicode consortium which is written like this: U+0639. This magic number is called a code point. The U+ means "Unicode" and the numbers are hexadecimal.
- #12: A Unicode transformation format (UTF) is an algorithmic mapping from every Unicode code point (except surrogate code points) to a unique byte sequence. The ISO/IEC 10646 standard uses the term “UCS transformation format” for UTF; the two terms are merely synonyms for the same concept.UTF-16 and UTF-32 use code units that are two and four bytes long respectively. For these UTFs, there are three sub-flavors: BE, LE and unmarked. The BE form uses big-endian byte serialization (most significant byte first), the LE form uses little-endian byte serialization (least significant byte first) and the unmarked form uses big-endian byte serialization by default, but may include a byte order mark at the beginning to indicate the actual byte serialization used.The tables below list numbers of bytes per code point, not per user visible "character" (or "grapheme cluster"). It can take multiple code points to describe a single grapheme cluster, so even in UTF-32, care must be taken when splitting or concatenating strings
- #13: how many bytes (what the C or C++ programming languages call a char) are used by the in-memory representation of the string; this is relevant for m ry or storage allocation and low-level processinghow many of the code units used by the character encoding form are in the string; this may be relevant, for example, when declaring the size of a character array or locating the character position in a string. It often represents the "length" of the string in APIs – this is completely dependant on the encoding in placehow many Unicode code points—the number of encoded characters—that are in the string.how many of what end users might consider "characters”The choice of which count to use and when depends on the use of the value, as well as the tradeoffs between efficiency and comprehension. For example, Java, Windows, and ICU use UTF-16 code unit counts for low-level string operations, but also supply higher level APIs for counting bytes, characters, or denoting boundaries between grapheme clusters, when circumstances require them
- #14: In computing, endian and endianness in the most common cases, refers to how bytes are ordered within computer memory. Computer memory is organized just the same as words on the page of a book or magazine, with the first words located in the upper left corner and the last in the lower right corner.Big Endian == spreadsheetLittle Endian == BACKWARDS WEIRDSo why does endianess matter?
- #15: So the people were forced to come up with the bizarre convention of storing a FE FF at the beginning of every Unicode stringThis is a Byte order mark or BOM (which makes PHP puke, btw)Thus was invented the brilliant concept of UTF-8. UTF-8 was another system for storing your string of Unicode code points, those magic U+ numbers, in memory using 8 bit bytes. In UTF-8, every code point from 0-127 is stored in a single byte. Only code points 128 and above are stored using 2, 3, in fact, up to 6 bytes.
- #16: Thus was invented the brilliant concept of UTF-8.UTF-8 was another system for storing your string of Unicode code points, those magic U+ numbers, in memory using 8 bit bytes.This has the neat side effect that English text looks exactly the same in UTF-8 as it did in ASCII, so Americans don't even notice anything wrong. Only the rest of the world has to jump through hoops.In UTF-8, every code point from 0-127 is stored in a single byte. Only code points 128 and above are stored using 2, 3, in fact, up to 6 bytes.Because 0 -127 look exactly the same in utf-8 as ansii and the bottom of oem pages life got a lot easier for stuff that already existed in english!! The rest of the world? Eh not so muchTechnically, ANSI should be the same as US-ASCII. It refers to the ANSI X3.4 standard, which is simply the ANSI organisation's ratified version of ASCII. Use of the top-bit-set characters is not defined in ASCII/ANSI as it is a 7-bit character set.
- #17: If you have a string, in memory, in a file, or in an email message, you have to know what encoding it is in or you cannot interpret it or display it to users correctlyThat encoding might be binary!There are over a hundred encodings and above code point 127, all bets are offSo when someone says “our application needs unicode support” what they REALLY mean is “our strings need to all be utf8”
- #18: The internet is a big place, there is more to the internet than north america – reach more mindsMojibake is an ugly thing that makes you look incompetentDo not piss people off by messing up their information (helgi and joel come to mind)
- #19: This is my friend helgiHelgi is from Iceland, although he lives in SF nowHelgi has a heck of a nameHelgi has and awesome name for making sure software can handle unicodeHelgi gets irritated when his conferences badges are all screwed up
- #20: Actual name is romanized as XinchenHui - he uses laurence for a lot of thingsHe works on a bunch of stuff like lua, taint, yaf, msgpack, helps on internals, and is generally awesomeBut can your site even store his name?
- #21: There’s a lot more to having a useful site for non-english speakers than just getting the characters displaying rightThere’s a host of other stuff involved
- #22: The distinction between internationalization and localization is subtle but important. Internationalization is the adaptation of products for potential use virtually everywhere, while localization is the addition of special features for use in a specificlocale.
- #23: Help for this can be found using locale codes and the ICU library – PHP’s intlYou’ll also need to keep track of timezonesStore all times in UTC – you will be grateful later on
- #25: There are millions of collation rules – and note that collation issues can bleed – in PHP it’s best to use ICU’s collation support, or rely on the collation of the storage mecanism you’re using like a database
- #27: This is the HARDEST part of doing any kind of localization for the web, actually.Most of the earlier items have useful apis to help with doing things, but layout and design is one of the most difficult to have configurableIt could be argued that as long as you manage to not totally violate your users beliefs and can at least flip the strings right to left they’ll figure out the rest of a flipped navigation layoutBut you still should be aware that those kinds of issues can exist
- #28: mb_string – threading issues, not feature complete, only way to use weird encodings in PHP filesIntl – all your base are belong to intl… except for zend_multibyteIconv – sometimes all you need is basics.5 – pcre – utf8 support with a little finaglingDO NOT USE gettextDO NOT DO NOT
- #29: Remember 5.3 is a bare bare BARE minimumIn 5.4 there were 74 new methods added to ICUIN 5.5 ICU got a string iterator and conversion capabilitiesIf you want GOOD support be on 5.5If you want minimum working do 5.3
- #30: PCRE is the pain in the ass one – if you have a system (I’m LOOKING AT YOU UBUNTU) that is determined to NOT use the up to date bundled pcre with PHP, you may get a pcre compiled without utf8 supportIn that case you either need to compile your own pcre and replace the system one or recompile your php and use the bundled pcre libraryEither fix works
- #31: PHP is written in CAll strings in PHP are char *A char in C is the smallest addressable unit of the machine that can contain basic character set. It is an integer type. Actual type can be either signed or unsigned depending on the implementation.They are generally 8 bitsIn PHP they need to be terminated by a null byte /0 to work with PHP’s (crappy) string functionalityIN PHP they are treated generally as binary strings – that is a bag of bits ;)
- #32: there's the thing that char * could point to one char but conventionally it's taken to point to a null-terminated stringand the whole char* == char[] thingbut probably don't bother about thatI'm being pedantic (minus the convoluted C pedant explanations)But this doesn’t work well for unicode encodings other than utf8
- #33: So C tried a new way –Windows went all in, standardized on ucs2 (later moved to true utf16) and allowed support for it in it’s entire apiLinux said – let’s just do a UTF8 locale and support utf8 for char *There is absolutely nothing worse than an ambiguous standard
- #34: SO the apis in PHP are not necessarily what you’d expectLet’s start with an absolute basic – strlenWhat does strlen ACTUALLY do? It reports the number of bytes in the string from the beginning, including any null bytes IN The string, up until the end but NOT including the null byte at the endYes you heard me right.
- #35: These are the fairly short list of functions which work either with utf8 or allow you to pass a charset to them
- #36: The locale information is maintained per process, not per thread. If you are running PHP on a multithreaded server API like IIS or Apache on Windows, you may experience sudden changes in locale settings while a script is running, though the script itself never called setlocale(). This happens due to other scripts running in different threads of the same process at the same time, changing the process-wide locale using setlocale().This is bullshit – this can make your server cryDo not rely on anything that relied on setting localeIf you are using fastcgi or worker mpm - owie
- #37: DO NOT USE GETTEXT ON A SERVERThe GNU gettext library works on a per-process, not per-thread basis. This means that in a multi-user setting such as the Apache web server it will only work with a prefork MPM (i.e. one process per user). Worker and other threaded MPMs will not work.In addition, many users control GNU gettext by setting system environment variables such as LANG. This is not a good solution for a web server environment due to an obvious race condition.
- #38: Did you know there is even more? Let’s go over just the most important stuff
- #39: Intlwil get you 90% of the way there with your needs… at least in the newest phpyou can iterate strings by grapheme, strtoupper and lower replacements, grapheme will give ou character counts and substring and searching
- #40: Lots of people ask what zend_multibyte doesIt allows you to have FILES in encodings that PHP wont choke onthat means utf16 or utf32 – antying beyond standard ansi code pages that doen’t do multibyte weirdness and utf8if you have a crappy old codebase that fixing would be too risky or painful this is probably your solutionit requires some fiddling with declarations and ini settings, but can “Fix” unicode issues a little more transparently. I would recommend this as a stopgap while you fix or rewrite or migrate the crap code
- #41: the output buffer handler is the BEST thing that iconv supports and really the most usefulyou set input and output encodings, and then use the handler you can also set all that up in your php.ini file if necessarythe other thing that iconv is great for is really it’s stream filter and output buffer handlerthose two things can make working with files in different character sets ENORMOUSLY more useful
- #43: Even if you get the encoding right in PHP…If the browser sends you garbage you’ll have garbageIf the database sends you garbage you’ll have garbageIf other tools (command line, writing out files) give you garbage you’ll get garbage
- #45: pdo needs 5.3.6 or highermysqli needs a newer libmysql or newer mysqlndif you’re using mysql – HAHAHA – good luckbasically almost every database has a method of telling the CLIENT – that’s the PHP extensionwhat it needs to get back from the databaseYou should make sure that your php encoding, your http encoding, your db encoding, and everything else all match!
- #47: What would a talk on unicode be without a wrap up of some of the best and worst examples of how to do i18n in a PHP applicationThese example go beyond
- #49: almost every framework out there gets it right. In the tradition of flexibility– most provide multiple ways to do the same thing with very little fiddlign on the part of the userand none of the good ones even support gettext
- #51: I do a lot of mentoring, and doing unicode with PHP is a pain – but we can make it less of one. Need a twofold approach – get a pecl version of intl working with the new functionality for older PHP (I’d say 5.3+ unlesssome poor so wants to do the 5.2 backports) and get the remainder of mb_string and iconv features into PHP so we can chuck themBONUS – drop in PHP scripts to replace iconv and mb_string calls with iconv! include instead of install extensions ;)If you’re interested and not afraid of some C – that’s my goal for this week, sit down with me and we’ll hack!There are also MORE features in ICU that PHP doesn’t have wrapped yet, believe it or not!(preferably with namespace magic not C evil) feasible (this might end up in PHP code)UPDATE THIS WITH PROGRESS
- #52: I’m a freelance developer – doing primarily C and C++ dev but available for other stuffAlso do a lot of open sourceAurora Eos Rose is the handle I’ve had forever – greek and roman goddesses of the dawn and aurora rose from sleeping beauty