

![Virtualizing Hadoop
• Motivation
– Hadoop-as-a-service (e.g. Amazon Elastic Map Reduce)
– Automated deployment and cost-effective management
– Dynamically scalable cluster size (e.g. # of nodes, resource allocation)
• Challenges
– I/O overhead
– Network overhead (message communication and data transfer)
• Related Work: virtualized vs. physical Hadoop
Virtualized Hadoop has an estimated overhead ranging between 2-10%
(reported in [1], [2], [3])
5th Workshop on Big Data Benchmarking 2014 3
[1] Buell, J.: A Benchmarking Case Study of Virtualized Hadoop Performance on VMware vSphere 5.
Tech. White Pap. VMware Inc. (2011).
[2] Buell, J.: Virtualized Hadoop Performance with VMware vSphere ®5.1. Tech. White Pap. VMware Inc. (2013).
[3] Microsoft: Performance of Hadoop on Windows in Hyper-V Environments. Tech. White Pap. Microsoft. (2013).](https://image.slidesharecdn.com/wbdb2014benchvirthadoopclusters-150810135310-lva1-app6891/85/WBDB-2014-Benchmarking-Virtualized-Hadoop-Clusters-3-320.jpg)


![Step I: Intel HiBench
• Benchmark suite for Hadoop (developed by Intel in 2010) (Huang et al. [4])
• 4 categories, 10 workloads & 3 types
• Metrics: Time (Sec) & Throughput (Bytes/Sec)
Category No Workload Tools Type
Micro Benchmarks
1 Sort MapReduce IO Bound
2 WordCount MapReduce CPU Bound
3 TeraSort MapReduce Mixed
4 TestDFSIOEnhanced MapReduce IO Bound
Web Search
5 Nutch Indexing Nutch, Lucene Mixed
6 Page Rank Pegasus Mixed
Machine Learning
7 Bayesian Classification Mahout Mixed
8 K-means Clustering Mahout Mixed
Analytical Query
9 Join Hive Mixed
10 Aggregation Hive Mixed
5th Workshop on Big Data Benchmarking 2014 6
[4] Huang, S. et al.: The HiBench benchmark suite: Characterization of the MapReduce-based data analysis.
Data Engineering Workshops (ICDEW), 2010](https://image.slidesharecdn.com/wbdb2014benchvirthadoopclusters-150810135310-lva1-app6891/85/WBDB-2014-Benchmarking-Virtualized-Hadoop-Clusters-6-320.jpg)


![Step II: Comparison Factors
The number of utilized VMs in the compared clusters should
be equal.
• Each additional VM increases the hypervisor overhead
(reported in [2], [5], [6])
• Utilizing more VMs may improve the overall system
performance [2]
The utilized hardware resources in a cluster should be equal.
5th Workshop on Big Data Benchmarking 2014 9
[2] Buell, J.: Virtualized Hadoop Performance with VMware vSphere ®5.1. Tech. White Pap. VMware Inc. (2013).
[5] Li, J. et al.: Performance Overhead Among Three Hypervisors: An Experimental Study using Hadoop Benchmarks.
Big Data (BigData Congress), 2013
[6] Ye, K. et al.: vHadoop: A Scalable Hadoop Virtual Cluster Platform for MapReduce-Based Parallel Machine Learning with
Performance Consideration. Cluster Computing Workshops (CLUSTER WORKSHOPS), 2012](https://image.slidesharecdn.com/wbdb2014benchvirthadoopclusters-150810135310-lva1-app6891/85/WBDB-2014-Benchmarking-Virtualized-Hadoop-Clusters-9-320.jpg)












WBDB 2014 Benchmarking Virtualized Hadoop Clusters
- 1. Benchmarking Virtualized Hadoop Clusters Todor Ivanov, Roberto V. Zicari Big Data Lab, Goethe University Frankfurt Alejandro Buchmann Database and Distributed Systems, TU Darmstadt 15th Workshop on Big Data Benchmarking 2014
- 2. Outline • Virtualizing Hadoop • Measuring Performance – Iterative Experimental Approach – Platform Setup – Experiments – Summary of Results • Lessons Learned • Next Steps 5th Workshop on Big Data Benchmarking 2014 2
- 3. Virtualizing Hadoop • Motivation – Hadoop-as-a-service (e.g. Amazon Elastic Map Reduce) – Automated deployment and cost-effective management – Dynamically scalable cluster size (e.g. # of nodes, resource allocation) • Challenges – I/O overhead – Network overhead (message communication and data transfer) • Related Work: virtualized vs. physical Hadoop Virtualized Hadoop has an estimated overhead ranging between 2-10% (reported in [1], [2], [3]) 5th Workshop on Big Data Benchmarking 2014 3 [1] Buell, J.: A Benchmarking Case Study of Virtualized Hadoop Performance on VMware vSphere 5. Tech. White Pap. VMware Inc. (2011). [2] Buell, J.: Virtualized Hadoop Performance with VMware vSphere ®5.1. Tech. White Pap. VMware Inc. (2013). [3] Microsoft: Performance of Hadoop on Windows in Hyper-V Environments. Tech. White Pap. Microsoft. (2013).
- 4. Objectives of Our Research Investigate and compare the performance between standard and separated data-compute cluster configurations. • How does the application performance change on a data-compute cluster? • What type of applications are more suitable for data-compute clusters? 5th Workshop on Big Data Benchmarking 2014 4 Standard Cluster Data-Compute Cluster
- 5. Methodology: Iterative Experimental Approach I. Choose a Big Data Benchmark II. Configure Hadoop Cluster III. Perform Experiments IV. Evaluate Results 5th Workshop on Big Data Benchmarking 2014 5
- 6. Step I: Intel HiBench • Benchmark suite for Hadoop (developed by Intel in 2010) (Huang et al. [4]) • 4 categories, 10 workloads & 3 types • Metrics: Time (Sec) & Throughput (Bytes/Sec) Category No Workload Tools Type Micro Benchmarks 1 Sort MapReduce IO Bound 2 WordCount MapReduce CPU Bound 3 TeraSort MapReduce Mixed 4 TestDFSIOEnhanced MapReduce IO Bound Web Search 5 Nutch Indexing Nutch, Lucene Mixed 6 Page Rank Pegasus Mixed Machine Learning 7 Bayesian Classification Mahout Mixed 8 K-means Clustering Mahout Mixed Analytical Query 9 Join Hive Mixed 10 Aggregation Hive Mixed 5th Workshop on Big Data Benchmarking 2014 6 [4] Huang, S. et al.: The HiBench benchmark suite: Characterization of the MapReduce-based data analysis. Data Engineering Workshops (ICDEW), 2010
- 7. Step II: Platform Setup • Platform layer (Hadoop Cluster) – vSphere Big Data Extension integrating Serengeti Server (version 1.0) – VM template hosting CentOS – Apache Hadoop (version 1.2.1) with default parameters: • 200MB Java Heap size • 64MB block size • 3 replication factor • Management layer (Virtualization) – VMWare vSphere 5.1 – ESXi and vCenter Servers • Hardware layer - Dell PowerEdge T420 server – 2 x Intel Xeon E5-2420 (1.9 GHz), 6 core CPUs – 32GB RAM – 4 x 1 TB, WD SATA disks Hardware Management (Virtualization) Application (HiBench Benchmark) Platform (Hadoop Cluster) CPUs Memory Storage 5th Workshop on Big Data Benchmarking 2014 7
- 8. (Known) Limitations • Single physical server (no physical network) • VMWare ESXi server hypervisor • Testing with default configurations (Serengeti & Hadoop) • Time constraints: – Input data sizes: 10/20/50GB – 3 test repetitions 5th Workshop on Big Data Benchmarking 2014 8
- 9. Step II: Comparison Factors The number of utilized VMs in the compared clusters should be equal. • Each additional VM increases the hypervisor overhead (reported in [2], [5], [6]) • Utilizing more VMs may improve the overall system performance [2] The utilized hardware resources in a cluster should be equal. 5th Workshop on Big Data Benchmarking 2014 9 [2] Buell, J.: Virtualized Hadoop Performance with VMware vSphere ®5.1. Tech. White Pap. VMware Inc. (2013). [5] Li, J. et al.: Performance Overhead Among Three Hypervisors: An Experimental Study using Hadoop Benchmarks. Big Data (BigData Congress), 2013 [6] Ye, K. et al.: vHadoop: A Scalable Hadoop Virtual Cluster Platform for MapReduce-Based Parallel Machine Learning with Performance Consideration. Cluster Computing Workshops (CLUSTER WORKSHOPS), 2012
- 10. Step II: Comparison Standard1/Data- Compute1 Standard Cluster Data-Compute Cluster 1) of the utilized hardware resources 2) of the utilized VMs ∆ – difference in performance 5th Workshop on Big Data Benchmarking 2014 10
- 11. Step II: Comparison Standard2/Data- Compute3 Standard Cluster Data-Compute Cluster 1) of the utilized hardware resources 2) of the utilized VMs ∆ – difference in performance 5th Workshop on Big Data Benchmarking 2014 11
- 12. Step II: Comparison Data- Compute1/2/3 Data-Compute Cluster Data-Compute Cluster 1) of the utilized hardware resources ∆ – difference in performance 5th Workshop on Big Data Benchmarking 2014 12
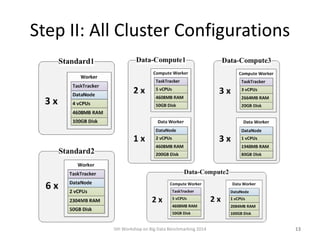
- 13. Step II: All Cluster Configurations 5th Workshop on Big Data Benchmarking 2014 13
- 14. Step III & IV: CPU Bound - WordCount • Configuration: 4 map/1 reduce tasks, 10/20/50 GB input data sizes • Times normalized with respect to baseline Standard1 • 38-47% better performance for Data-Compute cluster • Data-Compute1 (2CW & 1DW) ≈ Data-Compute2 (2CW & 2DW) Equal Number of VMs 3 VMs 6 VMs DataSize (GB) Diff. (%) Standard1/ Data-Comp1 Diff. (%) Standard2/ Data-Comp3 10 -40 -38 20 -41 -42 50 -43 -47 5th Workshop on Big Data Benchmarking 2014 14 1.00 1.00 1.00 1.75 1.74 1.74 0.71 0.71 0.700.71 0.71 0.70 1.26 1.22 1.19 0 0.5 1 1.5 2 10 20 50Data Size (GB) Standard1 Standard2 Data-Comp1 Data-Comp2 Data-Comp3 RatiotoStandard1
- 15. Step III & IV: Read I/O Bound – TestDFSIOEnh (1) • Configuration: 100MB file size, 10/20/50 GB input data sizes • Read times normalized with respect to baseline Standard1 • Standard1 (Standard Cluster) performs best Equal Number of VMs 3 VMs 6 VMs Data Size (GB) Diff. (%) Standard1/ Data-Comp1 Diff. (%) Standard2/ Data-Comp3 10 68 -18 20 71 -30 50 73 -46 RatiotoStandard1 5th Workshop on Big Data Benchmarking 2014 15 1.00 1.00 1.00 1.83 1.93 1.87 3.08 3.39 3.66 1.51 1.71 1.78 1.55 1.48 1.28 0.0 1.0 2.0 3.0 4.0 10 20 50Data Size (GB) Standard1 Standard2 Data-Comp1 Data-Comp2 Data-Comp3
- 16. Step III & IV: Read I/O Bound – TestDFSIOEnh (2) • Configuration: 100MB file size, 10/20/50 GB input data sizes • Read times normalized with respect to baseline Standard1 • Data-Comp1 (2CW & 1DW) > DC2 (2CW & 2DW) > DC3 (3CW & 3DW) More data nodes improve read performance in a Data-Compute cluster. Different Number of VMs 3 VMs 4 VMs 4 VMs 6 VMs Data Size (GB) Diff. (%) Data- Comp1/2 Diff. (%) Data- Comp2/3 10 -104 3 20 -99 -15 50 -106 -39 5th Workshop on Big Data Benchmarking 2014 16 1.00 1.00 1.00 1.83 1.93 1.87 3.08 3.39 3.66 1.51 1.71 1.78 1.55 1.48 1.28 0.0 1.0 2.0 3.0 4.0 10 20 50Data Size (GB) Standard1 Standard2 Data-Comp1 Data-Comp2 Data-Comp3 RatiotoStandard1
- 17. Step III & IV: Write I/O Bound – TestDFSIOEnh (1) • Configuration: 100MB file size, 10/20/50 GB input data sizes • Write times normalized with respect to baseline Standard1 • Data-Compute cluster (Data-Comp1, Data-Comp3) performs better Equal Number of VMs 3 VMs 6 VMs Data Size (GB) Diff. (%) Standard1/ Data-Comp1 Diff. (%) Standard2/ Data-Comp3 10 -10 4 20 -21 -14 50 -24 -1 5th Workshop on Big Data Benchmarking 2014 17 1.00 1.00 1.00 0.84 1.08 1.00 0.91 0.83 0.81 0.73 0.86 0.95 0.87 0.95 0.99 0.0 0.5 1.0 1.5 10 20 50 Data Size (GB) Standard1 Standard2 Data-Comp1 Data-Comp2 Data-Comp3 RatiotoStandard1
- 18. Step III & IV: Write I/O Bound – TestDFSIOEnh (2) • Configuration: 100MB file size, 10/20/50 GB input data sizes • Write times normalized with respect to baseline Standard1 • Data-Comp1 (2CW & 1DW) < Data-Comp3(3CW & 3DW) Having 2 extra Data Worker nodes increases the write overhead up to 19% in a Data-Compute cluster. • Data-Comp3 (6VMs) outperforms Standard1 (3VMs) Different Number of VMs 3 VMs 6 VMs 3 VMs 6 VMs Data Size (GB) Diff. (%) Data- Comp1/3 Diff. (%) Standard1/ Data-Comp3 10 -4 -15 20 13 -6 50 19 -1 5th Workshop on Big Data Benchmarking 2014 18 1.00 1.00 1.00 0.84 1.08 1.00 0.91 0.83 0.81 0.73 0.86 0.95 0.87 0.95 0.99 0.0 0.5 1.0 1.5 10 20 50 Data Size (GB) Standard1 Standard2 Data-Comp1 Data-Comp2 Data-Comp3 RatiotoStandard1
- 19. Summary of Results • Compute-intensive (i.e. CPU bound) workloads are suitable for Data- Compute clusters. (up to 47% faster) • Read-intensive (i.e. read I/O bound) workloads are suitable for Standard clusters. – For Data-Compute clusters adding more data nodes improves the read performance. (up to 39% better e.g. Data-Compute2/Data-Compute3) • Write-intensive (i.e. write I/O bound) workloads are suitable for Data- Compute clusters. (up to 15% faster e.g. Standard1/Data-Compute3 ) – Lower number of data nodes result in better write performance. 5th Workshop on Big Data Benchmarking 2014 19
- 20. Lessons Learned • Factors influencing cluster performance*: – Overall number of virtual nodes (VMs) in a cluster – Choosing cluster type (Standard or Data-Compute Hadoop cluster) – Number of nodes for each type (compute and data nodes) in a Data- Compute cluster * note: Limitations known! (slide 9) 5th Workshop on Big Data Benchmarking 2014 20
- 21. Next Steps • Repeat the experiments on virtualized multi-node cluster • Evaluate virtualized performance with other workloads • Experiments with larger data sets • Repeat the experiments using other hypervisors (e.g. OpenStack) 5th Workshop on Big Data Benchmarking 2014 21
- 22. Thank you! Questions & Feedback are very welcome! Contact info: Todor Ivanov [email protected] http://www.bigdata.uni-frankfurt.de/ 5th Workshop on Big Data Benchmarking 2014 22