Web smatch wod2012
Download as PPT, PDF•0 likes•600 views

WebSmatch is a platform for integrating open data from heterogeneous sources (1). It addresses problems with large numbers of data sources in different formats, including many Excel files that are poorly structured (2). WebSmatch crawls, classifies, documents and references data sources, then extracts and structures the data for visualization through APIs (3). It uses machine learning and concept matching to extract metadata from Excel files, including detecting tables, attributes, and concepts (4,5,6,7,10,11). The results are exported in structured formats like DSPL for third party use and visualization (13,14,16). Future work includes automating extraction at scale, clustering documents, and integrating with other tools (
















Web smatch wod2012
- 1. 1 WebSmatch : a platform for data and metadata integration Remi Coletta, Emmanuel Castanier, Patrick Valduriez, Christian Frisch, DuyHoa Ngo, Zohra Bellahsene
- 2. 2 Motivations Context: open data in France Problems • High number of data sources • Heterogeneous formats • Poorly structured Example (DataPublica): the web crawl for french open data sources found 148509 Excel files and only 369 RDF files Needs: integrate and visualize data sources to yield high- value information 2
- 3. 3 www.data-publica.com Business: market place for open data Functions: crawl, classify, document and reference data sources in a search engine The data is extracted and structured in a database in order to be visualized and accessible through APIs Problem: scale to high numbers of heterogeneous, poorly structured sources 3
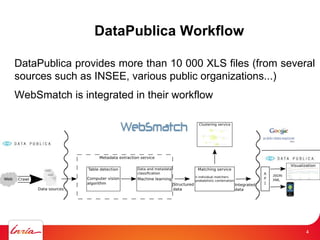
- 4. 4 DataPublica Workflow DataPublica provides more than 10 000 XLS files (from several sources such as INSEE, various public organizations...) WebSmatch is integrated in their workflow 4
- 5. 5 Example of input URL : http://www.data-publica.com/publication/4736 Problem : where are data and metadata? incomplete lines, unnamed attributes Existing tools such as OpenII or Google Refine work only on clean files 5
- 6. 6 Example of input URL : http://www.data-publica.com/publication/4736 Find data table Remove blank lines or columns 6
- 7. 7 Example of input URL : http://www.data-publica.com/publication/4736 Find metadata such as titles Identify collections for bidimensionnal tables 7
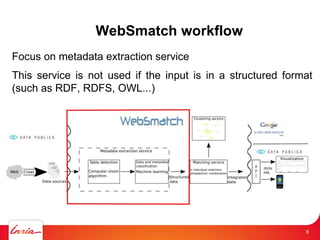
- 8. 8 WebSmatch workflow Focus on metadata extraction service This service is not used if the input is in a structured format (such as RDF, RDFS, OWL...) 8
- 9. 9 MetaData Extraction: XLS example First step : Table detection using vision algorithms (dilate/erode) 9
- 10. 10 MetaData Extraction: XLS example Second step : Attribute detection using machine learning on cell content and neigboorhood 10
- 11. 11 MetaData Extraction: XLS example Third step : automatic detection of concepts using YAM++ (14 matching techniques such as string matching, instance based, wordnet...) YAM++ came 1st and 2nd at OAEI 2011 : http://oaei.ontologymatching.org/2011/results/ 11
- 12. 12 WebSmatch Workflow Focus on matching service Relies on YAM++, combining different metrics (String, Wordnet, Instance based) 12
- 13. 13 Data Visualization Structured export formats easy to use for third parties : DSPL DSPL : DataSet Publishing Language from Google Inc. see https://developers.google.com/public-data/ For bidimensionnal tables, we need to denormalize as DSPL uses flat CSV files for data => 13
- 14. Exporting the Results : integrated 14 metadata How to make richer datasets : aggregation or intersection – using generic concepts such as time or location – find a specific concept using the matching 14
- 15. 15 Visualizing the Results 15
- 16. 16 Visualizing the Results http://api.data-publica.com/…/content.json? limit=10&filter={revenue_fiscal_par_foyer:{$gt:25000}} • Multi format (json, xml, spreadsheet,csv) • Geolocalized queries • Mashups 16
- 17. 17 Perspectives 1. Automating large volume extraction: confidence / machine learning 2. Clustering documents (on specific concepts & concept instances) • Integration with other tools • Google Refine • RDF export 17
- 18. 18 Conclusion WebSmatch is a flexible environment for Open Data integration End-to-end process: importing, data cleansing and integrating data sources DSPL export format for visualization Real validation with DataPublica data sources 18