Webinar: MongoDB + Hadoop
19 likes5,429 views

The document discusses the integration of Hadoop and MongoDB, highlighting Hadoop as a framework for distributed processing of large datasets, and MongoDB as an operational store for online data management. It covers various technical details including MapReduce functions, input/output configurations, and common use cases such as behavioral analytics and fraud detection. Additionally, it provides insight into data management capabilities and tools like HDFS, YARN, and Pig for data processing.








![10
Processing Sensor Data
{
"_id" : ObjectId("556172a53004b760dde8a488"),
”deviceId" : 556172530004,
"value" : 6205,
"timestamp" : ISODate(”2015-06-02T02:03:17.906Z"),
"loc" : [
-174.95596353219008,
40.654427078258834
]
} Average Sensor Value By
Device
Time Interval
Location Bucket](https://image.slidesharecdn.com/hadoopwebinar1-150618200623-lva1-app6891/85/Webinar-MongoDB-Hadoop-10-320.jpg)
![11
Processing Sensor Data
{
"_id" : ObjectId("556172a53004b760dde8a488"),
”deviceId" : 556172530004,
"value" : 6205,
"timestamp" : ISODate(”2015-06-02T02:03:17.906Z"),
"loc" : [
-174.95596353219008,
40.654427078258834
]
} Average Sensor Value By
Device
Time Interval
Location Bucket](https://image.slidesharecdn.com/hadoopwebinar1-150618200623-lva1-app6891/85/Webinar-MongoDB-Hadoop-11-320.jpg)
![12
Processing Sensor Data
{
"_id" : ObjectId("556172a53004b760dde8a488"),
”deviceId" : 556172530004,
"value" : 6205,
"timestamp" : ISODate(”2015-06-02T02:03:17.906Z"),
"loc" : [
-174.95596353219008,
40.654427078258834
]
} Average Sensor Value By
Device
Time Interval
Location Bucket](https://image.slidesharecdn.com/hadoopwebinar1-150618200623-lva1-app6891/85/Webinar-MongoDB-Hadoop-12-320.jpg)
![13
Processing Sensor Data
{
"_id" : ObjectId("556172a53004b760dde8a488"),
”deviceId" : 556172530004,
"value" : 6205,
"timestamp" : ISODate(”2015-06-02T02:03:17.906Z"),
"loc" : [
-174.95596353219008,
40.654427078258834
]
} Average Sensor Value By
Device
Time Interval
Location Bucket](https://image.slidesharecdn.com/hadoopwebinar1-150618200623-lva1-app6891/85/Webinar-MongoDB-Hadoop-13-320.jpg)































Webinar: MongoDB + Hadoop
- 1. Hadoop + MongoDB { Name: ‘Bryan Reinero’, Title: ‘Developer Advocate’, Twitter: ‘@blimpyacht’, Email: ‘[email protected]’ }
- 2. 2 Hadoop A framework for distributed processing of large data sets • Terabyte and petabyte datasets • Data warehousing • Advanced analytics • Not a database • No indexes • Batch processing
- 4. 4 Data Management Hadoop Fault tolerance Batch processing Coarse-grained operations Unstructured Data MongoDB High availability Mutable data Fine-grained operations Flexible Schemas
- 5. 5 Data Management Hadoop Offline Processing Analytics Data Warehousing MongoDB Online Operations Application Operational
- 7. 7 MongoDB as an Operational Store Application Server
- 8. 8 Use Cases • Behavioral analytics • Segmentation • Fraud detection • Prediction • Pricing analytics • Sales analytics
- 9. What does it do?
- 10. 10 Processing Sensor Data { "_id" : ObjectId("556172a53004b760dde8a488"), ”deviceId" : 556172530004, "value" : 6205, "timestamp" : ISODate(”2015-06-02T02:03:17.906Z"), "loc" : [ -174.95596353219008, 40.654427078258834 ] } Average Sensor Value By Device Time Interval Location Bucket
- 11. 11 Processing Sensor Data { "_id" : ObjectId("556172a53004b760dde8a488"), ”deviceId" : 556172530004, "value" : 6205, "timestamp" : ISODate(”2015-06-02T02:03:17.906Z"), "loc" : [ -174.95596353219008, 40.654427078258834 ] } Average Sensor Value By Device Time Interval Location Bucket
- 12. 12 Processing Sensor Data { "_id" : ObjectId("556172a53004b760dde8a488"), ”deviceId" : 556172530004, "value" : 6205, "timestamp" : ISODate(”2015-06-02T02:03:17.906Z"), "loc" : [ -174.95596353219008, 40.654427078258834 ] } Average Sensor Value By Device Time Interval Location Bucket
- 13. 13 Processing Sensor Data { "_id" : ObjectId("556172a53004b760dde8a488"), ”deviceId" : 556172530004, "value" : 6205, "timestamp" : ISODate(”2015-06-02T02:03:17.906Z"), "loc" : [ -174.95596353219008, 40.654427078258834 ] } Average Sensor Value By Device Time Interval Location Bucket
- 14. 14 MapReduce map() { emit( { key: ObjectId(…), value: 6205 } ); emit( { key: bucketByLoc( loc ), value: 6205 } ); emit( { key: bucketByDate( timestamp ), value: value } ); }
- 15. 15 MapReduce {key: ObjectId(…), value: 6205 } map() { emit( { key: ObjectId(…), value: 6205 } ); emit( { key: bucketByLoc( loc ), value: 6205 } ); emit( { key: bucketByDate( timestamp ), value: value } ); }
- 16. 16 MapReduce map() { emit( { key: ObjectId(…), value: 6205 } ); emit( { key: bucketByLoc( loc ), value: 6205 } ); emit( { key: bucketByDate( timestamp ), value: value } ); } {key: zone_a, value: 6205}
- 17. 17 MapReduce map() { emit( { key: ObjectId(…), value: 6205 } ); emit( { key: bucketByLoc( loc ), value: 6205 } ); emit( { key: bucketByDate( timestamp ), value: value } ); } { key: m06_d01_h02, value: 6205}
- 18. 18 MapReduce
- 19. 19 MapReduce key: zonea, value: 6025
- 20. 20 MapReduce key: zonea, value: 4904
- 21. 21 MapReduce key: zonea, value: 6338
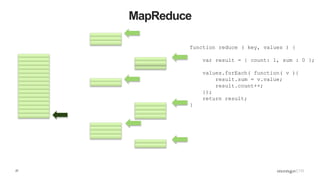
- 26. 26 MapReduce function reduce ( key, values ) { var result = { count: 1, sum : 0 }; values.forEach( function( v ){ result.sum = v.value; result.count++; }); return result; }
- 27. 27 MapReduce function reduce ( key, values ) { var result = { count: 1, sum : 0 }; values.forEach( function( v ){ result.sum = v.value; result.count++; }); return result; }
- 29. 29 HDFS and YARN • Hadoop Distributed File System (HDFS) – Distributed file-system that stores data on commodity machines in a Hadoop cluster • Yet Another Resource Negotiator (YARN) – Resource management platform responsible for managing and scheduling compute resources in a Hadoop cluster
- 30. 30 Hadoop Distributed File System (HDFS) DATA NODE DATA NODE DATA NODE DATA NODE Client Read / Writes Replication NAME NODE Metadata Operations
- 31. 31 Yet Another Resource Negotiator COMPUTE NODE Client NODE MANAGER NODE MANAGER RESOURCE MANAGER APPLICATION MASTER CONTAINER CONTAINER CONTAINER
- 33. 33 What You’re Gonna Need A reducer class extends org.apache.hadoop.mapreduce.Reducer A mapper class extends org.apache.hadoop.mapreduce.Mapper Hadoop Connector Jar https://github.com/mongodb/mongo-hadoop
- 34. 34 MapReduce Configuration • MongoDB input – mongo.job.input.format = com.mongodb.hadoop.MongoInputFormat – mongo.input.uri = mongodb://mydb:27017/db1.collection1 • MongoDB output – mongo.job.output.format = com.mongodb.hadoop.MongoOutputFormat – mongo.output.uri = mongodb://mydb:27017/db1.collection2 • BSON input/output – mongo.job.input.format = com.hadoop.BSONFileInputFormat – mapred.input.dir = hdfs:///tmp/database.bson – mongo.job.output.format = com.hadoop.BSONFileOutputFormat – mapred.output.dir = hdfs:///tmp/output.bson
- 35. 35 Yet Another Resource Negotiator COMPUTE NODE Client NODE MANAGER NODE MANAGER RESOURCE MANAGER APPLICATION MASTER CONTAINER CONTAINER CONTAINER Bin/hadoop jar MyJob.jar MongoDB_Hadoop_Connector.jar
- 36. 36 Cluster MONGOS SHARD A SHARDB SHARD C SHARD D MONGOS Client
- 37. 37
- 39. 39 extends MongoSplitter class List<InputSplit> calculateSplits()
- 40. 40 • High-level platform for creating MapReduce • Pig Latin abstracts Java into easier-to-use notation • Executed as a series of MapReduce applications • Supports user-defined functions (UDFs) Pig
- 41. 41 samples = LOAD 'mongodb://127.0.0.1:27017/sensor.logs' USING com.mongodb.hadoop.pig.MongoLoader(’deviceId:int,value:double'); grouped = GROUP samples by deviceId; sample_stats = FOREACH grouped { mean = AVG(samples.value); GENERATE group as deviceId, mean as mean; } STORE sample_stats INTO 'mongodb://127.0.0.1:27017/sensor.stats' USING com.mongodb.hadoop.pig.MongoStorage;
- 42. 42 • Data warehouse infrastructure built on top of Hadoop • Provides data summarization, query, and analysis • HiveQL is a subset of SQL • Support for user-defined functions (UDFs)
- 43. 43 • Powerful built-in transformations and actions – map, reduceByKey, union, distinct, sample, intersection, and more – foreach, count, collect, take, and many more An engine for processing Hadoop data. Can perform MapReduce in addition to streaming, interactive queries, and machine learning.
- 45. Thanks! { name: ‘Bryan Reinero’, title: ‘Developer Advocate’, twitter: ‘@blimpyacht’, code: ‘github.com/breinero’ email: ‘[email protected]’ }