What Is Q Learning In Reinforcement Learning | Q Learning Explained | Q Learning | Simplilearn
0 likes89 views

Q-learning is a reinforcement learning algorithm that aims to determine the optimal action-selection policy based on state-action rewards. It employs key concepts like temporal difference learning, exploration vs. exploitation, and the Bellman equation. Q-learning is advantageous for its adaptability and simplicity but may face challenges in noisy environments and convergence speed.





What Is Q Learning In Reinforcement Learning | Q Learning Explained | Q Learning | Simplilearn
- 2. Q-Learning Reinforcement Learning ? Understanding the Basics l Definition Q-learning Q-learning is a type of reinforcement learning algorithm used in machine learning to find the optimal action-selection policy for any given problem
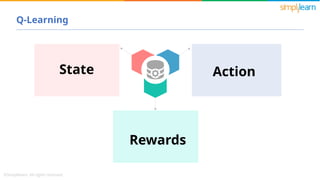
- 4. Q-Values Q-Learning Rewards & Episodes Temporal Difference Exploration & Exploitation Key Components of Q-Learning
- 5. Temporal Difference Determining Q-value Bellman`s ford Equation
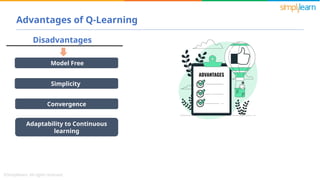
- 6. Model Free Disadvantages Simplicity Convergence Advantages of Q-Learning Adaptability to Continuous learning
- 7. Memory Usage Advantages Slow Convergence Trade-off Disadvantages of Q-Learning Noisy Environment