What’s new in Apache Spark 2.3 and Spark 2.4
12 likes5,578 views

The document presents an overview of the updates and features in Apache Spark versions 2.3 and 2.4, emphasizing improvements such as the new Data Source API v2, native vectorized ORC reader, and the introduction of Pandas UDFs. It discusses enhancements in structured streaming, support for Kubernetes, and various modifications to data sources including Avro and image formats. Additionally, the text highlights significant performance optimizations and stability improvements across the platform.







![8 © Hortonworks Inc. 2011–2018. All rights reserved
Stable Codegen
• [SPARK-22510] [SPARK-22692] Stabilize the codegen framework to avoid hitting the
64KB JVM bytecode limit on the Java method and Java compiler constant pool limit.
• [SPARK-21871] Turn off whole-stage codegen when the bytecode of the generated Java
function is larger than ‘spark.sql.codegen.hugeMethodLimit’. The limit of method
bytecode for JIT optimization on HotSpot is 8K.](https://image.slidesharecdn.com/4pm1600moorwhatsnewinspark2-181018002420/85/What-s-new-in-Apache-Spark-2-3-and-Spark-2-4-8-320.jpg)
















![26 © Hortonworks Inc. 2011–2018. All rights reserved
Others Notable Changes
• [SPARK-16496] Text datasource is now able to read a whole file as single row (wholeText
option)
• [SPARK-18136] pip install pyspark works on Windows now!
• [SPARK-21472] ArrowColumnVector interface is exposed to interact with Spark side
• [SPARK-19810] Scala 2.10 is dropped](https://image.slidesharecdn.com/4pm1600moorwhatsnewinspark2-181018002420/85/What-s-new-in-Apache-Spark-2-3-and-Spark-2-4-26-320.jpg)

![28 © Hortonworks Inc. 2011–2018. All rights reserved
Apache Spark 2.4
Barrier Execution
Apache Spark 3.0
• [SPARK-24374] barrier execution mode
• [SPARK-24374] barrier execution mode
• [SPARK-24579] optimized data exchange
• [SPARK-24615] accelerator-aware scheduling
See also Project Hydrogen: Unifying State-of-the-art AI and Big Data in Apache Spark by Reynold Xin
See also Project Hydrogen: State-of-the-Art Deep Learning on Apache Spark by Xiangrui Meng](https://image.slidesharecdn.com/4pm1600moorwhatsnewinspark2-181018002420/85/What-s-new-in-Apache-Spark-2-3-and-Spark-2-4-28-320.jpg)




![33 © Hortonworks Inc. 2011–2018. All rights reserved
Flexible Streaming Sink
• Exposing output rows of each microbatch as a DataFrame
• foreachBatch(f: Dataset[T] => Unit) Scala/Java/Python APIs in DataStreamWriter.](https://image.slidesharecdn.com/4pm1600moorwhatsnewinspark2-181018002420/85/What-s-new-in-Apache-Spark-2-3-and-Spark-2-4-33-320.jpg)
![34 © Hortonworks Inc. 2011–2018. All rights reserved
Kafka Client 2.0.0
• [SPARK-18057] Upgraded Kafka client version from 0.10.0.1 to 2.0.0
• [SPARK-25005] Support “kafka.isolation.level” to read only committed records from
Kafka topics that are written using a transactional producer.
• [SPARK-25501] Kafka delegation token support (ongoing)
• Kafka added delegation token support in version 1.1.0](https://image.slidesharecdn.com/4pm1600moorwhatsnewinspark2-181018002420/85/What-s-new-in-Apache-Spark-2-3-and-Spark-2-4-34-320.jpg)
![35 © Hortonworks Inc. 2011–2018. All rights reserved
Avro Data Source
• Apache Avro (https://avro.apache.org)
• A data serialization format
• Widely used in the Spark and Hadoop ecosystem, especially for Kafka-based data pipelines.
• Spark-Avro package (https://github.com/databricks/spark-avro)
• Spark SQL can read and write the Avro data.
• Inlining Spark-Avro package [SPARK-24768]
• Better experience for first-time users of Spark SQL and structured streaming
• Expect further improve the adoption of structured streaming](https://image.slidesharecdn.com/4pm1600moorwhatsnewinspark2-181018002420/85/What-s-new-in-Apache-Spark-2-3-and-Spark-2-4-35-320.jpg)


![38 © Hortonworks Inc. 2011–2018. All rights reserved
Avro Data Source
• Options:
• compression: compression codec in write
• ignoreExtension: if ignore .avro or not in read
• recordNamespace: record namespace in write
• recordName: top root record name in write
• avroSchema: avro schema to use
• Logical type support:
• Date [SPARK-24772]
• Decimal [SPARK-24774]
• Timestamp [SPARK-24773]](https://image.slidesharecdn.com/4pm1600moorwhatsnewinspark2-181018002420/85/What-s-new-in-Apache-Spark-2-3-and-Spark-2-4-38-320.jpg)




![43 © Hortonworks Inc. 2011–2018. All rights reserved
Apache Spark and Kubernetes
• New Spark scheduler backend
• PySpark support [SPARK-23984]
• SparkR support [SPARK-24433]
• Client-mode support [SPARK-23146]
• Support for mounting K8S volumes [SPARK-23529]
Scala 2.12 (Beta) Support
Build Spark against Scala 2.12 [SPARK-14220]](https://image.slidesharecdn.com/4pm1600moorwhatsnewinspark2-181018002420/85/What-s-new-in-Apache-Spark-2-3-and-Spark-2-4-43-320.jpg)

![45 © Hortonworks Inc. 2011–2018. All rights reserved
Data Source Changes
• CSV
• Option samplingRatio
• for schema inference [SPARK-23846]
• Option enforceSchema
• for throwing an exception when user-
specified schema doesn‘t match the CSV
header [SPARK-23786]
• Option encoding
• for specifying the encoding of outputs.
[SPARK-19018]
• JSON
• Option dropFieldIfAllNull
• for ignoring column of all null values or
empty array/struct during JSON schema
inference [SPARK-23772]
• Option lineSep
• for defining the line separator that should
be used for parsing [SPARK-23765]
• Option encoding
• for specifying the encoding of inputs and
outputs. [SPARK-23723]](https://image.slidesharecdn.com/4pm1600moorwhatsnewinspark2-181018002420/85/What-s-new-in-Apache-Spark-2-3-and-Spark-2-4-45-320.jpg)
![46 © Hortonworks Inc. 2011–2018. All rights reserved
Data Source Changes
• Parquet
• Push down
• STRING [SPARK-23972]
• Decimal [SPARK-24549]
• Timestamp [SPARK-24718]
• Date [SPARK-23727]
• Byte/Short [SPARK-24706]
• StringStartsWith [SPARK-24638]
• IN [SPARK-17091]
• ORC
• Native ORC reader is on by default
[SPARK-23456]
• Turn on ORC filter push-down by
default [SPARK-21783]
• Use native ORC reader to read Hive
serde tables by default [SPARK-
22279]](https://image.slidesharecdn.com/4pm1600moorwhatsnewinspark2-181018002420/85/What-s-new-in-Apache-Spark-2-3-and-Spark-2-4-46-320.jpg)
![47 © Hortonworks Inc. 2011–2018. All rights reserved
Data Source Changes
• JDBC
• Option queryTimeout
• for the number of seconds the the driver will wait for a Statement object to execute.
[SPARK-23856]
• Option query
• for specifying the query to read from JDBC [SPARK-24423]
• Option pushDownFilters
• for specifying whether the filter pushdown is allowed [SPARK-24288]
• Option cascadeTruncate [SPARK-22880]](https://image.slidesharecdn.com/4pm1600moorwhatsnewinspark2-181018002420/85/What-s-new-in-Apache-Spark-2-3-and-Spark-2-4-47-320.jpg)
![48 © Hortonworks Inc. 2011–2018. All rights reserved
Other Notable Changes
• [SPARK-16406] Analyzer: Improve performance of LogicalPlan.resolve
• Add an indexing structure to resolve(...) in order to find potential matches quicker.
• [SPARK-23963] Properly handle large number of columns in query on text-based Hive
table
• Turns a list to array, makes a hive table scan 10 times faster when there are a lot of columns.
• [SPARK-23486] Analyzer: Cache the function name from the external catalog for
lookupFunctions](https://image.slidesharecdn.com/4pm1600moorwhatsnewinspark2-181018002420/85/What-s-new-in-Apache-Spark-2-3-and-Spark-2-4-48-320.jpg)
![49 © Hortonworks Inc. 2011–2018. All rights reserved
Other Notable Changes
• [SPARK-23243] Fix RDD.repartition() data correctness issue
• [SPARK-24296] Support replicating blocks larger than 2 GB
• [SPARK-24307] Support sending messages over 2GB from memory
• [SPARK-24596] Non-cascading Cache Invalidation
• Non-cascading mode for temporary views and DataSet.unpersist()
• Cascading mode for the rest
• [SPARK-23880] Do not trigger any job for caching data
• [SPARK-23510][SPARK-24312] Support Hive 2.2 and Hive 2.3 metastore
• [SPARK-23711] Add fallback generator for UnsafeProjection
• [SPARK-24626] Parallelize location size calculation in Analyze Table](https://image.slidesharecdn.com/4pm1600moorwhatsnewinspark2-181018002420/85/What-s-new-in-Apache-Spark-2-3-and-Spark-2-4-49-320.jpg)




What’s new in Apache Spark 2.3 and Spark 2.4
- 1. 1 © Hortonworks Inc. 2011–2018. All rights reserved What’s New in Apache Spark 2.3 and Spark 2.4 Hyukjin Kwon Software Engineer 2018
- 2. 2 © Hortonworks Inc. 2011–2018. All rights reserved Hyukjin Kwon • Apache Spark Committer • Hortonworks Software Engineer • I know a little bit of … • PySpark, SparkSQL, SparkR, building and infra stuff in Apache Spark • Distributed computing and indexing • Python internal • Quite active in Apache Spark community (@HyukjinKwon in GitHub)
- 3. 3 © Hortonworks Inc. 2011–2018. All rights reserved Apache Spark 2.3.0 Agenda Apache Spark 2.4.0 • Data Source API V2 • Native Vectorized ORC Reader • Pandas UDFs for PySpark • Continuous Stream Processing • Apache Spark and Kubernetes • Others Notable changes See also What’s new in Apache Spark 2.3 by Xiao Li and Wenchen Fan • Barrier Execution • Pandas UDFs: Grouped Aggregate • Avro/Image Data Source • Higher-order Functions • Apache Spark and Kubernetes • Other Notable Changes See also What’s new in Upcoming Apache Spark 2.4 by Xiao Li
- 4. 4 © Hortonworks Inc. 2011–2018. All rights reserved Apache Spark 2.3.0
- 5. 5 © Hortonworks Inc. 2011–2018. All rights reserved Data Source API V1 Data Source API V2 • Leak upper level API in the data source (DataFrame/SQLContext) • Difficult to support source-specific catalog (multiple catalog support, see also SPARK- 24252) • Hard to extend the Data Source API for more optimizations • Zero transaction guarantee in the write APIs
- 6. 6 © Hortonworks Inc. 2011–2018. All rights reserved Data Source API V2 Data Source API V2 • Java friendly (written in Java). • No dependency on upper level APIs (DataFrame/RDD/…). • Easy to extend, can add new optimizations while keeping backward compatibility. • Can report physical information like size, partition, etc. • Streaming source/sink support. • A flexible and powerful, transactional write API. • No change to end users. See also Apache Spark Data Source V2 by Wenchen Fan and Gengliang Wang
- 7. 7 © Hortonworks Inc. 2011–2018. All rights reserved Native Vectorized ORC Reader • Native ORC read and write: ‘spark.sql.orc.impl’ to ‘native’. • Vectorized ORC reader: ‘spark.sql.orc.enableVectorizedReader’ to ‘true’ See also ORC Improvement in Apache Spark 2.3 by Dongjoon Hyun
- 8. 8 © Hortonworks Inc. 2011–2018. All rights reserved Stable Codegen • [SPARK-22510] [SPARK-22692] Stabilize the codegen framework to avoid hitting the 64KB JVM bytecode limit on the Java method and Java compiler constant pool limit. • [SPARK-21871] Turn off whole-stage codegen when the bytecode of the generated Java function is larger than ‘spark.sql.codegen.hugeMethodLimit’. The limit of method bytecode for JIT optimization on HotSpot is 8K.
- 9. 9 © Hortonworks Inc. 2011–2018. All rights reserved Normal UDF Pandas UDFs (a.k.a. Vectorized UDFs) Apache Spark Python Worker Internal Spark data Convert to standard Java type Pickled Unpickled Evaluate row by row Convert to Python data
- 10. 10 © Hortonworks Inc. 2011–2018. All rights reserved Pandas UDF Pandas UDFs (a.k.a. Vectorized UDFs) Internal Spark data Apache Arrow format Convert to Pandas (cheap) Vectorized operation by Pandas API Apache Spark Python Worker
- 11. 11 © Hortonworks Inc. 2011–2018. All rights reserved Pandas UDF Pandas UDFs (a.k.a. Vectorized UDFs) Internal Spark data Apache Arrow format Convert to Pandas (cheap) Vectorized operation by Pandas API Apache Spark Python Worker
- 12. 12 © Hortonworks Inc. 2011–2018. All rights reserved Pandas UDF Pandas UDFs (a.k.a. Vectorized UDFs) See also Introducing Pandas UDFs for PySpark by Li Jin
- 13. 13 © Hortonworks Inc. 2011–2018. All rights reserved Conversion To/From Pandas With Apache Arrow • Enable Apache Arrow optimization: ‘spark.sql.execution.arrow.enabled’ to ‘true’. See also Speeding up PySpark with Apache Arrow by Bryan Cutler
- 14. 14 © Hortonworks Inc. 2011–2018. All rights reserved Structured Streaming Continuous Stream Processing
- 15. 15 © Hortonworks Inc. 2011–2018. All rights reserved Structured Streaming: Microbatch Continuous Stream Processing See also Continuous Processing in Structured Streaming by Josh Torres
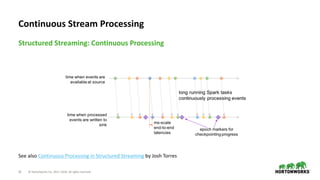
- 16. 16 © Hortonworks Inc. 2011–2018. All rights reserved Structured Streaming: Continuous Processing Continuous Stream Processing See also Continuous Processing in Structured Streaming by Josh Torres
- 17. 17 © Hortonworks Inc. 2011–2018. All rights reserved Structured Streaming: Continuous Processing Continuous Stream Processing See also Spark Summit Keynote Demo by Michael Armbrust https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html#continuous-processing
- 18. 18 © Hortonworks Inc. 2011–2018. All rights reserved Stream-to-Stream Joins See also Introducing Stream-Stream Joins in Apache Spark 2.3 by Tathagata Das and Joseph Torres
- 19. 19 © Hortonworks Inc. 2011–2018. All rights reserved Apache Spark and Kubernetes See also Running Spark on Kubernetes
- 20. 20 © Hortonworks Inc. 2011–2018. All rights reserved Apache Spark 2.3.0 Apache Spark and Kubernetes Apache Spark 2.4.0 (Roadmap) • Client mode • Dynamic resource allocation + external shuffle service • Python and R support • Submission client local dependencies + Resource staging server (RSS) • Non-secured and Kerberized HDFS access (injection of Hadoop configuration) • Supports Kubernetes 1.6 and up • Supports cluster mode only • Static resource allocation only • Supports Java and Scala applications • Can use container-local and remote dependencies that are downloadable
- 21. 21 © Hortonworks Inc. 2011–2018. All rights reserved Image Support in Spark • Convert from compressed Images format (e.g., PNG and JPG) to raw representation of an image for OpenCV • One record per one image file See also SPARK-21866 by Ilya Matiach, and Deep Learning Pipelines for Apache Spark
- 22. 22 © Hortonworks Inc. 2011–2018. All rights reserved (Stateless) History Server History Server Using K-V Store • Requires storing app lists and UI in the memory • Requires reading/parsing the whole log file See also SPARK-18085 and the proposal by Marcelo Vanzin
- 23. 23 © Hortonworks Inc. 2011–2018. All rights reserved History Server Using K-V Store History Server Using K-V Store • Store app lists and UI in a persistent K-V store (LevelDB) • Set ‘spark.history.store.path’ to use this feature • The event log written by lower versions is still compatible See also SPARK-18085 and the proposal by Marcelo Vanzin
- 24. 24 © Hortonworks Inc. 2011–2018. All rights reserved R Structured Streaming https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html See also SSR: Structured Streaming on R for Machine Learning by Felix Cheung
- 25. 25 © Hortonworks Inc. 2011–2018. All rights reserved R Native Function Execution Stability See also SPARK-21093
- 26. 26 © Hortonworks Inc. 2011–2018. All rights reserved Others Notable Changes • [SPARK-16496] Text datasource is now able to read a whole file as single row (wholeText option) • [SPARK-18136] pip install pyspark works on Windows now! • [SPARK-21472] ArrowColumnVector interface is exposed to interact with Spark side • [SPARK-19810] Scala 2.10 is dropped
- 27. 27 © Hortonworks Inc. 2011–2018. All rights reserved Apache Spark 2.4.0
- 28. 28 © Hortonworks Inc. 2011–2018. All rights reserved Apache Spark 2.4 Barrier Execution Apache Spark 3.0 • [SPARK-24374] barrier execution mode • [SPARK-24374] barrier execution mode • [SPARK-24579] optimized data exchange • [SPARK-24615] accelerator-aware scheduling See also Project Hydrogen: Unifying State-of-the-art AI and Big Data in Apache Spark by Reynold Xin See also Project Hydrogen: State-of-the-Art Deep Learning on Apache Spark by Xiangrui Meng
- 29. 29 © Hortonworks Inc. 2011–2018. All rights reserved Pandas UDFs: Grouped Aggregate Pandas UDFs https://github.com/apache/spark/commit/9786ce66c https://github.com/apache/spark/commit/b2ce17b4c
- 30. 30 © Hortonworks Inc. 2011–2018. All rights reserved Pandas UDFs: Grouped Aggregate Pandas UDFs https://github.com/apache/spark/pull/22620/commits/06a7bd0c Internal Spark data Apache Arrow format Convert to Pandas (cheap) Vectorized operation by Pandas API Apache Spark Python Worker
- 31. 31 © Hortonworks Inc. 2011–2018. All rights reserved Eager Evaluation • Set ‘spark.sql.repl.eagerEval.enabled’ to true to enable eager evaluation in Jupyter
- 32. 32 © Hortonworks Inc. 2011–2018. All rights reserved Eager Evaluation • Set ‘spark.sql.repl.eagerEval.enabled’ to true to enable eager evaluation in Jupyter See also (ongoing) SPARK-24572 for Eagar Evaluation at R side
- 33. 33 © Hortonworks Inc. 2011–2018. All rights reserved Flexible Streaming Sink • Exposing output rows of each microbatch as a DataFrame • foreachBatch(f: Dataset[T] => Unit) Scala/Java/Python APIs in DataStreamWriter.
- 34. 34 © Hortonworks Inc. 2011–2018. All rights reserved Kafka Client 2.0.0 • [SPARK-18057] Upgraded Kafka client version from 0.10.0.1 to 2.0.0 • [SPARK-25005] Support “kafka.isolation.level” to read only committed records from Kafka topics that are written using a transactional producer. • [SPARK-25501] Kafka delegation token support (ongoing) • Kafka added delegation token support in version 1.1.0
- 35. 35 © Hortonworks Inc. 2011–2018. All rights reserved Avro Data Source • Apache Avro (https://avro.apache.org) • A data serialization format • Widely used in the Spark and Hadoop ecosystem, especially for Kafka-based data pipelines. • Spark-Avro package (https://github.com/databricks/spark-avro) • Spark SQL can read and write the Avro data. • Inlining Spark-Avro package [SPARK-24768] • Better experience for first-time users of Spark SQL and structured streaming • Expect further improve the adoption of structured streaming
- 36. 36 © Hortonworks Inc. 2011–2018. All rights reserved Avro Data Source • from_avro/to_avro functions to read and write Avro data within a DataFrame instead of just files. • Example: • Decode the Avro data into a struct • Filter by column `favorite_color` • Encode the column `name` in Avro format
- 37. 37 © Hortonworks Inc. 2011–2018. All rights reserved Avro Data Source • Refactor Avro Serializer and Deserializer • External • Arrow Data -> Row -> InternalRow • Native • Arrow Data -> InternalRow
- 38. 38 © Hortonworks Inc. 2011–2018. All rights reserved Avro Data Source • Options: • compression: compression codec in write • ignoreExtension: if ignore .avro or not in read • recordNamespace: record namespace in write • recordName: top root record name in write • avroSchema: avro schema to use • Logical type support: • Date [SPARK-24772] • Decimal [SPARK-24774] • Timestamp [SPARK-24773]
- 39. 39 © Hortonworks Inc. 2011–2018. All rights reserved Image Data Source • Spark datasource for image format • ImageSchema deprecated use instead: • SQL syntax support • Partition discovery
- 40. 40 © Hortonworks Inc. 2011–2018. All rights reserved Higher-order Functions • Takes functions to transform complex datatype like map, array and struct
- 41. 41 © Hortonworks Inc. 2011–2018. All rights reserved Higher-order Functions
- 42. 42 © Hortonworks Inc. 2011–2018. All rights reserved Built-in Functions • New or extended built-in functions for ArrayTypes and MapTypes • 26 functions for ArrayTypes • transform, filter, reduce, array_distinct, array_intersect, array_union, array_except, array_join, array_max, array_min, ... • 8 functions for MapTypes • map_from_arrays, map_from_entries, map_entries, map_concat, map_filter, map_zip_with, transform_keys, transform_values
- 43. 43 © Hortonworks Inc. 2011–2018. All rights reserved Apache Spark and Kubernetes • New Spark scheduler backend • PySpark support [SPARK-23984] • SparkR support [SPARK-24433] • Client-mode support [SPARK-23146] • Support for mounting K8S volumes [SPARK-23529] Scala 2.12 (Beta) Support Build Spark against Scala 2.12 [SPARK-14220]
- 44. 44 © Hortonworks Inc. 2011–2018. All rights reserved PySpark Custom Worker • Configuration to select the modules for daemon and worker in PySpark • Set ‘spark.python.daemon.module’and/or ‘spark.python.worker.module’ tothe worker or daemon modules See also Remote Python Debugging 4 Spark
- 45. 45 © Hortonworks Inc. 2011–2018. All rights reserved Data Source Changes • CSV • Option samplingRatio • for schema inference [SPARK-23846] • Option enforceSchema • for throwing an exception when user- specified schema doesn‘t match the CSV header [SPARK-23786] • Option encoding • for specifying the encoding of outputs. [SPARK-19018] • JSON • Option dropFieldIfAllNull • for ignoring column of all null values or empty array/struct during JSON schema inference [SPARK-23772] • Option lineSep • for defining the line separator that should be used for parsing [SPARK-23765] • Option encoding • for specifying the encoding of inputs and outputs. [SPARK-23723]
- 46. 46 © Hortonworks Inc. 2011–2018. All rights reserved Data Source Changes • Parquet • Push down • STRING [SPARK-23972] • Decimal [SPARK-24549] • Timestamp [SPARK-24718] • Date [SPARK-23727] • Byte/Short [SPARK-24706] • StringStartsWith [SPARK-24638] • IN [SPARK-17091] • ORC • Native ORC reader is on by default [SPARK-23456] • Turn on ORC filter push-down by default [SPARK-21783] • Use native ORC reader to read Hive serde tables by default [SPARK- 22279]
- 47. 47 © Hortonworks Inc. 2011–2018. All rights reserved Data Source Changes • JDBC • Option queryTimeout • for the number of seconds the the driver will wait for a Statement object to execute. [SPARK-23856] • Option query • for specifying the query to read from JDBC [SPARK-24423] • Option pushDownFilters • for specifying whether the filter pushdown is allowed [SPARK-24288] • Option cascadeTruncate [SPARK-22880]
- 48. 48 © Hortonworks Inc. 2011–2018. All rights reserved Other Notable Changes • [SPARK-16406] Analyzer: Improve performance of LogicalPlan.resolve • Add an indexing structure to resolve(...) in order to find potential matches quicker. • [SPARK-23963] Properly handle large number of columns in query on text-based Hive table • Turns a list to array, makes a hive table scan 10 times faster when there are a lot of columns. • [SPARK-23486] Analyzer: Cache the function name from the external catalog for lookupFunctions
- 49. 49 © Hortonworks Inc. 2011–2018. All rights reserved Other Notable Changes • [SPARK-23243] Fix RDD.repartition() data correctness issue • [SPARK-24296] Support replicating blocks larger than 2 GB • [SPARK-24307] Support sending messages over 2GB from memory • [SPARK-24596] Non-cascading Cache Invalidation • Non-cascading mode for temporary views and DataSet.unpersist() • Cascading mode for the rest • [SPARK-23880] Do not trigger any job for caching data • [SPARK-23510][SPARK-24312] Support Hive 2.2 and Hive 2.3 metastore • [SPARK-23711] Add fallback generator for UnsafeProjection • [SPARK-24626] Parallelize location size calculation in Analyze Table
- 50. 50 © Hortonworks Inc. 2011–2018. All rights reserved What About Apache Spark 3.0? Spark 2.2.0 RC1 2017/05 Spark 2.2.0 released 2018/07 Spark 2.2.0 RC2, RC3, RC4, RC5 2017/06 Spark 2.2.0 RC6 2017/07 Spark 2.3.0 RC1 2018/01 Spark 2.3.0 RC2, RC3, RC4, RC5 2018/02 Spark 2.3.0 released 2018/02 Spark 2.4.0 RC1 2018/09 Spark 3.0.0 2019/05 (?) Spark 2.4.0 RC2 2018/10 Spark 2.4.0 2018/10 (?) See also the thread in Spark dev mailing list for Spark 3.0 discussion
- 51. 51 © Hortonworks Inc. 2011–2018. All rights reserved Newer Integration for Apache Hive with Apache Spark • Apache Hive 3 support: Apache Spark provides a basic Hive compatibility • Apache Hive ACID table support • Structured Streaming Support • Apache Ranger integration support • Use LLAP and vectorized read/write – fast! See also this article for Hive warehouse connector
- 52. 52 © Hortonworks Inc. 2011–2018. All rights reserved Questions?
- 53. 53 © Hortonworks Inc. 2011–2018. All rights reserved Thank you