What's next for Big Data? -- Apache Spark
22 likes4,042 views

The document discusses Apache Spark as a leading platform for big data, emphasizing its capabilities in integrating SQL, machine learning, and streaming analytics. It highlights the advantages of Spark such as code reuse, fast in-memory data sharing, and extensive use cases in personalization and marketing automation. Additionally, it presents usage statistics and the transition of Spark in production since 2013, showcasing its effectiveness in handling large data volumes.




















What's next for Big Data? -- Apache Spark
- 1. WHAT’S NEXT FOR BIG DATA? APACHE SPARK
- 3. 3 TUMRA - Big Data Week, May 2014 Spark is … “One platform to rule them all” … and blurs boundary between SQL, machine learning, streams & graphs
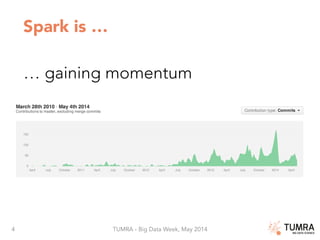
- 4. 4 TUMRA - Big Data Week, May 2014 Spark is … … gaining momentum
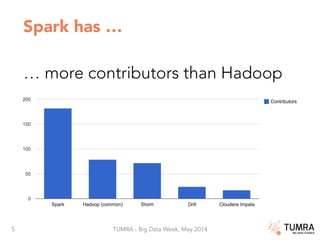
- 5. 5 TUMRA - Big Data Week, May 2014 Spark has … … more contributors than Hadoop
- 6. 6 TUMRA - Big Data Week, May 2014 Spark can … Source: Databricks
- 7. 7 TUMRA - Big Data Week, May 2014 Spark Stack Source: Databricks Hadoop (HDFS)
- 8. 8 TUMRA - Big Data Week, May 2014 Why Spark? - Code reuse across batch, streaming and interactive applications - Easy API from Scala, Java & Python - In-memory data sharing FAAAAAAST!!! Check out http://spark.apache.org
- 9. 9 TUMRA - Big Data Week, May 2014 CASE STUDY: PERSONALISATION & MARKETING AUTOMATION
- 10. 10 TUMRA - Big Data Week, May 2014 Our history with Spark - Early adopters; poc in Dec ‘12 - In production since March ‘13 - Running on Amazon EC2 - Ad-hoc analysis and reporting - Machine learning model building - Integrates to our real-time dashboards
- 11. 11 TUMRA - Big Data Week, May 2014 Use Case: Personalisation
- 12. 12 TUMRA - Big Data Week, May 2014 Use Case: Personalisation (cont’d) - Matching visitors to products - 50% of visitors are ‘new’ and have no history to work with - Blend of pre-computation and real- time recommendations
- 13. 13 TUMRA - Big Data Week, May 2014 Use Case: Marketing Automation - Collect user engagement data across websites and mobile apps - Increase subscription rates - Identity users at risk of churn - Automated personalised marketing
- 14. 14 TUMRA - Big Data Week, May 2014 Data Volumes & Velocity - 29M events per day - Peak rates ~800 events / second - All events streamed to Kafka - 10B archived events in Amazon S3
- 15. 15 TUMRA - Big Data Week, May 2014 How we use Spark Amazon S3 (HDFS interface) Apache Ka>a Data CollecAon API (Akka) & Connectors
- 16. 16 TUMRA - Big Data Week, May 2014 Spark gives us … - Unified platform for machine learning and graph analytics - Ability to experiment at huge scale - SQL interfaces to existing tools - Code reuse from data scientists to production workloads
- 17. 17 TUMRA - Big Data Week, May 2014 WANT TO KNOW MORE?
- 18. 18 TUMRA - Big Data Week, May 2014 http://spark.apache.org
- 19. 19 TUMRA - Big Data Week, May 2014 Spark Summit 2014
- 20. 20 TUMRA - Big Data Week, May 2014 Spark London Meetup
- 21. 21 TUMRA - Big Data Week, May 2014 Commercial Support & Certification
- 22. 22 TUMRA - Big Data Week, May 2014 THANK YOU @tumra tumra.com slideshare.net/tumra