Writing Continuous Applications with Structured Streaming in PySpark
5 likes2,259 views

The document discusses the use of Apache Spark for building continuous applications with structured streaming, emphasizing the challenges of stream processing and advantages of using Spark. It covers various components such as data integration, transformation, and real-time analytics, showcasing the power of structured streaming in dealing with complex data. The talk includes a demonstration of continuous applications and resources for further exploration of Spark's capabilities.





































![Traditional ETL
• Raw, dirty, un/semi-structured is data dumped as files
• Periodic jobs run every few hours to convert raw data to structured
data ready for further analytics
• Hours of delay before taking decisions on latest data
• Problem: Unacceptable when time is of essence
• [intrusion detection, anomaly detection,etc.]
38
file
dump
seconds hours
table
10101010](https://image.slidesharecdn.com/pysparkstructuredstreamingfinal-180409215523/85/Writing-Continuous-Applications-with-Structured-Streaming-in-PySpark-38-320.jpg)


![Reading from Kafka
raw_data_df = spark.readStream
.format("kafka")
.option("kafka.boostrap.servers",...)
.option("subscribe", "topic")
.load()
rawData dataframe has
the following columns
key value topic partition offset timestamp
[binary] [binary] "topicA" 0 345 1486087873
[binary] [binary] "topicB" 3 2890 1486086721](https://image.slidesharecdn.com/pysparkstructuredstreamingfinal-180409215523/85/Writing-Continuous-Applications-with-Structured-Streaming-in-PySpark-41-320.jpg)
















Writing Continuous Applications with Structured Streaming in PySpark
- 1. Writing Continuous Applications with Structured Streaming in PySpark Jules S. Damji, Databricks AnacondaConf,Austin,TX 4/10/2018
- 2. I have used Apache Spark 2.x Before…
- 3. Apache Spark Community & DeveloperAdvocate @ Databricks DeveloperAdvocate@ Hortonworks Software engineering @: Sun Microsystems, Netscape, @Home, VeriSign, Scalix, Centrify, LoudCloud/Opsware, ProQuest Program Chair Spark + AI Summit https://www.linkedin.com/in/dmatrix @2twitme
- 4. Simplify Big Data and AI with Databricks Unified Analytics Platform DATA WAREHOUSESCLOUD STORAGE HADOOP STORAGEIoT / STREAMING DATA DATABRICKS SERVERLESSRemoves Devops & Infrastructure Complexity DATABRICKS RUNTIME Reliability Eliminates Disparate Tools with Optimized Spark Explore Data Train Models Serve Models DATABRICKS COLLABORATIVE NOTEBOOKSIncreases Data Science Productivity by 5x Databricks Enterprise Security Open Extensible API’s Accelerates & Simplifies Data Prep for Analytics Performance
- 5. Agenda for Today’s Talk • What’s Big Data Done To Us • What and Why Apache Spark • Why Streaming Applications are Difficult • What’s Structured Streaming • Anatomy of a Continunous Application • Demo • Q & A
- 6. What’s Big Data Done to Us Today’s Madness in a Minute
- 7. What’s Big Data Done to Us Tomorrow’s Madness Magnified
- 8. What’s Big Data Done to Us Permeated our livesSource : MIT
- 9. What’s Apache Spark & Why
- 10. What is Apache Spark? • General cluster computing engine that extends MapReduce • Rich set of APIs and libraries • Unified Engine • Large community: 1000+ orgs, clusters up to 8000 nodes Apache Spark, Spark and Apache are trademarks of the Apache Software Foundation SQLStreaming ML Graph … DL
- 11. Unique Thing about Spark • Unification: same engine and same API for diverse use cases • Streaming, batch, or interactive • ETL, SQL, machine learning, or graph
- 12. Why Unification?
- 13. Why Unification? • MapReduce: a general engine for batch processing
- 14. MapReduce Generalbatch processing Pregel Dremel Millwheel Drill Giraph ImpalaStorm S4 . . . Specialized systems for newworkloads Big Data Systems Yesterday Hard to manage, tune, deployHard to combine in pipelines
- 15. MapReduce Generalbatch processing Unified engine Big Data Systems Today ? Pregel Dremel Millwheel Drill Giraph ImpalaStorm S4 . . . Specialized systems for newworkloads
- 16. Benefits of Unification 1. Simpler to use and operate 2. Code reuse: e.g. only write monitoring, FT, etc once 3. New apps that span processing types: e.g. interactive queries on a stream, online machine learning
- 17. Fast and General Cluster Computing Scala SQL EC2 Kubernetes Automatic Parallelism and Fault-tolerance GCP YARN
- 18. An Analogy Specialized devices Unified device New applications
- 19. Why Streaming Applications are Inherently Difficult?
- 21. Complexities in stream processing COMPLEX DATA Diverse data formats (json, avro, binary, …) Data can be dirty, late, out-of-order COMPLEX SYSTEMS Diverse storage systems (Kafka, S3, Kinesis, RDBMS, …) System failures COMPLEX WORKLOADS Combining streaming with interactive queries Machine learning
- 22. Structured Streaming stream processing on Spark SQL engine fast, scalable, fault-tolerant rich, unified, high level APIs deal with complex data and complex workloads rich ecosystem of data sources integrate with many storage systems
- 23. you should not have to reason about streaming
- 24. Treat Streams as Unbounded Tables 24 data stream unbounded inputtable newdata in the data stream = newrows appended to a unboundedtable
- 25. you should write simple queries & Apache Spark should continuously update the answer
- 26. DataFrames, Datasets, SQL input = spark.readStream .format("kafka") .option("subscribe", "topic") .load() result = input .select("device", "signal") .where("signal > 15") result.writeStream .format("parquet") .start("dest-path") Logical Plan Read from Kafka Project device, signal Filter signal > 15 Writeto Parquet Apache Spark automatically streamifies! Spark SQL converts batch-like query to a series of incremental execution plans operating on new batches of data Series of Incremental Execution Plans Kafka Source Optimized Operator codegen, off- heap, etc. Parquet Sink Optimized Physical Plan process newdata t = 1 t = 2 t = 3 process newdata process newdata
- 27. Structured Streaming – Processing Modes 27
- 28. Structured Streaming Processing Modes 28
- 30. Streaming word count Anatomy of a Streaming Query
- 31. Anatomy of a Streaming Query: Step 1 spark.readStream .format("kafka") .option("subscribe", "input") .load() . Source • Specify one or more locations to read data from • Built in support for Files/Kafka/Socket, pluggable.
- 32. Anatomy of a Streaming Query: Step 2 from pyspark.sql import Trigger spark.readStream .format("kafka") .option("subscribe", "input") .load() .groupBy(“value.cast("string") as key”) .agg(count("*") as “value”) Transformation • Using DataFrames,Datasets and/or SQL. • Internal processingalways exactly- once.
- 33. Anatomy of a Streaming Query: Step 3 from pyspark.sql import Trigger spark.readStream .format("kafka") .option("subscribe", "input") .load() .groupBy(“value.cast("string") as key”) .agg(count("*") as “value”) .writeStream() .format("kafka") .option("topic", "output") .trigger("1 minute") .outputMode(OutputMode.Complete()) .option("checkpointLocation", "…") .start() Sink • Accepts the output of each batch. • When supported sinks are transactional and exactly once (Files).
- 34. Anatomy of a Streaming Query: Output Modes from pyspark.sql import Trigger spark.readStream .format("kafka") .option("subscribe", "input") .load() .groupBy(“value.cast("string") as key”) .agg(count("*") as 'value’) .writeStream() .format("kafka") .option("topic", "output") .trigger("1 minute") .outputMode("update") .option("checkpointLocation", "…") .start() Output mode – What's output • Complete – Output the whole answer every time • Update – Output changed rows • Append– Output new rowsonly Trigger – When to output • Specifiedas a time, eventually supportsdata size • No trigger means as fast as possible
- 35. Anatomy of a Streaming Query: Checkpoint from pyspark.sql import Trigger spark.readStream .format("kafka") .option("subscribe", "input") .load() .groupBy(“value.cast("string") as key”) .agg(count("*") as 'value) .writeStream() .format("kafka") .option("topic", "output") .trigger("1 minute") .outputMode("update") .option("checkpointLocation", "…") .start() Checkpoint • Tracks the progress of a query in persistent storage • Can be used to restart the query if there is a failure. • trigger( Trigger. Continunous(“ 1 second”))
- 36. Fault-tolerance with Checkpointing Checkpointing – tracks progress (offsets) of consuming data from the source and intermediate state. Offsets and metadata saved as JSON Can resume after changing your streaming transformations end-to-end exactly-once guarantees process newdata t = 1 t = 2 t = 3 process newdata process newdata write ahead log
- 38. Traditional ETL • Raw, dirty, un/semi-structured is data dumped as files • Periodic jobs run every few hours to convert raw data to structured data ready for further analytics • Hours of delay before taking decisions on latest data • Problem: Unacceptable when time is of essence • [intrusion detection, anomaly detection,etc.] 38 file dump seconds hours table 10101010
- 39. Streaming ETL w/ Structured Streaming Structured Streaming enables raw data to be available as structured data as soon as possible 39 seconds table 10101010
- 40. Streaming ETL w/ Structured Streaming Example Json data being received in Kafka Parse nested json and flatten it Store in structured Parquet table Get end-to-end failure guarantees from pyspark.sql import Trigger rawData = spark.readStream .format("kafka") .option("kafka.boostrap.servers",...) .option("subscribe", "topic") .load() parsedData = rawData .selectExpr("cast (value as string) as json")) .select(from_json("json", schema).as("data")) .select("data.*") # do your ETL/Transformation query = parsedData.writeStream .option("checkpointLocation", "/checkpoint") .partitionBy("date") .format("parquet") .trigger( Trigger. Continunous(“5 second”)) .start("/parquetTable")
- 41. Reading from Kafka raw_data_df = spark.readStream .format("kafka") .option("kafka.boostrap.servers",...) .option("subscribe", "topic") .load() rawData dataframe has the following columns key value topic partition offset timestamp [binary] [binary] "topicA" 0 345 1486087873 [binary] [binary] "topicB" 3 2890 1486086721
- 42. Transforming Data Cast binary value to string Name it column json Parse json string and expand into nested columns, name it data parsedData = rawData .selectExpr("cast (value as string) as json") .select(from_json("json", schema).as("data")) .select("data.*") json { "timestamp": 1486087873, "device": "devA", …} { "timestamp": 1486082418, "device": "devX", …} data (nested) timestamp device … 1486087873 devA … 1486086721 devX … from_json("json") as "data"
- 43. Transforming Data Cast binary value to string Name it column json Parse json string and expand into nested columns, name it data Flatten the nested columns parsedData = rawData .selectExpr("cast (value as string) as json") .select(from_json("json", schema).as("data")) .select("data.*") powerful built-in Python APIs to perform complex data transformations from_json, to_json, explode,... 100s offunctions (see our blogpost & tutorial)
- 44. Writing to Save parsed data as Parquet table in the given path Partition files by date so that future queries on time slices of data is fast e.g. query on last 48 hours of data query = parsedData.writeStream .option("checkpointLocation", ...) .partitionBy("date") .format("parquet") .start("/parquetTable") #pathname
- 46. Summary • Big Data is eating the world— for good & bad • Apache Spark best suited for unified analytics & processing at scale • Structured Streaming APIs Enables Continunous Applications • Demonstrated Continunous Application
- 47. Resources • Getting Started Guide with Apache Spark on Databricks • docs.databricks.com • Spark Programming Guide • Structured Streaming Programming Guide • Anthology of Technical Assets for Structured Streaming • Databricks Engineering Blogs • spark-packages.org
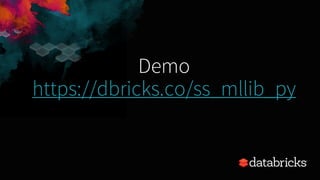
- 49. ML Model Store continuous application Goal: end-to-end continuous application Structured Streaming and Machine Learning Scoring and Serving in Real-time Ad hocquerieskafka directory/files
- 50. Hardest part of AI isn’t AI “Hidden Technical Debt in Machine Learning Systems", Google NIPS 2015 The hardest part of AI is Big Data ML Code
- 51. Big Data was the Missing Link for AI BIG DATA Customer Data Emails/Web pages Click Streams Sensor data (IoT) Video/Speech … GREAT RESULTS
- 52. Here is a basic slide Suspendisseullamcorpervel odio a varius • Pellentesque habitant morbi tristiqu • enectus et netuset malesuada fames ac turpis egestas • ut erat dapibus lobortis purus sed gravida augu • efficitur a risus placerat porta nullam molestie malesuada velit et auctor
- 53. Here are some logos
- 54. HEADER CAN BE BOLD ALL CAPS LIKE THIS Here is a comparison slide • Quisque tortor quam, posuere sed sagittis et, iaculis a urna. In malesuada in orci ut lacinia • Sed bibendum sed mauris egestas pellentesque • Vestibulum bibendum sagittis odio quis tincidunt augue consequat e • Aliquam purus leo, interdum eu urna vitae • Etiam in arcu gravida, tincidunt magna ve faucibus • Donec laoreet vel quam eu condimentum
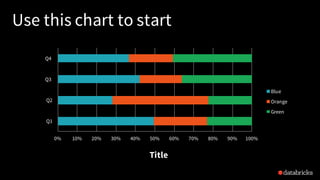
- 55. 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% Q1 Q2 Q3 Q4 Title Blue Orange Green Use this chart to start
- 56. Here are some icons to use - scalable DB Benefits DB Features General /Data Science Icons can be recoloredwithinPowerpoint — see: format picture/ picture color / recolor Orange, Green, and Black versions (no recolorationnecessary) can be found in go/icons
- 57. More icons Industries Security Spark Benefits Spark Features
- 59. Slide for Large Question or Section Headers
- 60. Thank You Parting words or contact information go here.