




![Our Requirements for the Accuracy Metrics
● Applicable for the elements having multiplemembership
● Applicable for Large Datasets: ideally O(N), runtime up to O(N2
)
Families with the accuracy metrics satisfying our requirements:
● Pair Counting Based Metrics: OmegaIndex [Collins,1988]
● Cluster Matching Based Metrics: AverageF1score [Yang,2013]
● Information Theory Based Metrics: GeneralizedNMI [Esquivel,2012]
Problem: accuracy values interpretability and the metric selection.
6](https://image.slidesharecdn.com/xmeasures-accuracyevaluationofoverlappingandmulti-resolutionclusteringalgorithmsonlargedatasets-190302020855/85/Xmeasures-Accuracy-evaluation-of-overlapping-and-multi-resolution-clustering-algorithms-on-large-datasets-slides-6-320.jpg)





![Omega Index (Fuzzy ARI) [Collins,1988]
Omega Index (𝛀) counts the number of pairs of elements occurring in
exactly the same number of clusters as in the number of categories and
adjusted to the expected number of such pairs:
12
,
,
C’ - ground-truth
(categories)
C - produced cls.](https://image.slidesharecdn.com/xmeasures-accuracyevaluationofoverlappingandmulti-resolutionclusteringalgorithmsonlargedatasets-190302020855/85/Xmeasures-Accuracy-evaluation-of-overlapping-and-multi-resolution-clustering-algorithms-on-large-datasets-slides-12-320.jpg)



![Average F1 Score [Yang,2013]
F1a is defined as the average of the weighted F1 scores of a) the best
matching ground-truth clusters to the formed clusters and b) the best
matching formed clusters to the ground-truth clusters:
16
,
F1 - F1-measure
[Rijsbergen, 1974]](https://image.slidesharecdn.com/xmeasures-accuracyevaluationofoverlappingandmulti-resolutionclusteringalgorithmsonlargedatasets-190302020855/85/Xmeasures-Accuracy-evaluation-of-overlapping-and-multi-resolution-clustering-algorithms-on-large-datasets-slides-16-320.jpg)




![Generalized Normalized Mutual Information (NMI)
NMI is Mutual Information I(C’:C) normalized by the max or mean
value of the unconditional entropy H of the clusterings C’, C:
22
,
,
GNMI
[Esquivel,2012]
uses a stochastic
process to
compute MI.](https://image.slidesharecdn.com/xmeasures-accuracyevaluationofoverlappingandmulti-resolutionclusteringalgorithmsonlargedatasets-190302020855/85/Xmeasures-Accuracy-evaluation-of-overlapping-and-multi-resolution-clustering-algorithms-on-large-datasets-slides-22-320.jpg)






Xmeasures - Accuracy evaluation of overlapping and multi-resolution clustering algorithms on large datasets (slides)
- 1. Accuracy Evaluation of Overlapping and Multi-resolution Clustering Algorithms on Large Datasets IEEE BigComp 2019 Artem Lutov, Mourad Khayati and Philippe Cudré-Mauroux eXascale Infolab, University of Fribourg, Switzerland https://github.com/eXascaleInfolab/xmeasures https://bit.ly/xmeasures-slides
- 2. Contributions ● Extension of the existent accuracy metrics to increasetheirdiscriminativepower ● Optimization of the accuracy metrics calculation to speedup the evaluation process ● Recommendations for the applicability of the accuracy metrics considering interpretability of their values 2
- 3. Informal Objective Generalized Evaluation of the ClusteringQuality Generalized: for any (large and complex) clustering results (datasets) Complex clustering results: multiplemembership of the elements Quality: the extrinsic quality (accuracy) quantifiers the expectedresults (comparing to the ground-truth) unlike the intrinsic quality quantifying some statistical properties of the formed clusters 3
- 4. Complex Clustering Results(Multiple Membership) 44 Racing cars Overlapping Clusters Clusters on Various Resolutions Blue cars Jeeps Cars Racing cars Bikes Racing & blue cars Bikes
- 5. Matching the clusterings (unordered sets of elements) even with the elements having a single membership may yield multiplebestmatches: => Strictclusterslabeling is not always possible and undesirable. Many dedicated accuracy metrics are designed but few of them are applicable for the elements with multiplemembership. Accuracy Evaluation for Clusterings 5 Produced Ground-truth Dark or Cyan? Yellow
- 6. Our Requirements for the Accuracy Metrics ● Applicable for the elements having multiplemembership ● Applicable for Large Datasets: ideally O(N), runtime up to O(N2 ) Families with the accuracy metrics satisfying our requirements: ● Pair Counting Based Metrics: OmegaIndex [Collins,1988] ● Cluster Matching Based Metrics: AverageF1score [Yang,2013] ● Information Theory Based Metrics: GeneralizedNMI [Esquivel,2012] Problem: accuracy values interpretability and the metric selection. 6
- 7. Interpretability of the Accuracy Values The four formalconstraints identify aspects of the clusteringquality being captured by different accuracy metrics: ● Homogeneity ● Completeness ● Rag Bag ● Size vs Quality (Micro Weighting) 7 Amigó et al., 2009 Rosenberg et al., 2007
- 8. Homogeneity 8 Clusters should not mix elements belonging to different categories. Low High* Figures are taken from Amigó et al., 2009
- 9. Completeness 9 Elements belonging to the same category should be clustered together. Low High* Figures are taken from Amigó et al., 2009
- 10. Rag Bag 10 Elements with low relevance to the categories (e.g., noise) should be preferably assigned to the less homogeneous clusters (macro-scale, low-resolution, coarse-grained or top-level clusters in a hierarchy). Low High
- 11. Size vs Quality (Micro Weighting) 11 Low High A small assignment error in a large cluster is preferable to a large number of similar errors in small clusters.
- 12. Omega Index (Fuzzy ARI) [Collins,1988] Omega Index (𝛀) counts the number of pairs of elements occurring in exactly the same number of clusters as in the number of categories and adjusted to the expected number of such pairs: 12 , , C’ - ground-truth (categories) C - produced cls.
- 13. Omega Index Counterexample A counter-example for the Omega Index (highly overlapping clusters): 13 Ground-truth C1’: 1 2 3 C2’: 2 3 4 C3’: 3 4 1 C4’: 4 1 2 Low C1: 1 2 C2: 3 4 High C1: 1 2 C2: 2 3 C3: 3 4 C4: 4 1 Omega Index 0 0
- 14. Soft Omega Index Soft Omega Index take into account pairs present in different number of clusters by normalizing smaller number of occurrences of each pair of elements in all clusters of one clustering by the larger number of occurrences in another clustering: 14 ,
- 15. Omega Index vs Soft Omega Index A counter-example for the Omega Index (highly overlapping clusters): 15 Ground-truth C1’: 1 2 3 C2’: 2 3 4 C3’: 3 4 1 C4’: 4 1 2 Low C1: 1 2 C2: 3 4 High C1: 1 2 C2: 2 3 C3: 3 4 C4: 4 1 Low High Omega 0 0 Soft Omega 0 0.33
- 16. Average F1 Score [Yang,2013] F1a is defined as the average of the weighted F1 scores of a) the best matching ground-truth clusters to the formed clusters and b) the best matching formed clusters to the ground-truth clusters: 16 , F1 - F1-measure [Rijsbergen, 1974]
- 17. Mean F1 Scores: F1h F1h uses harmonic instead of the arithm. mean to address F1a ≳ 0.5 for the clusters produced from all combinations of the nodes (F1C‘,C = 1 since for each category there exists the exactly matching cluster, F1C,C’ →0 since majority of the clusters have low similarity to the categories): 17 , for the contribution m of the nodes:
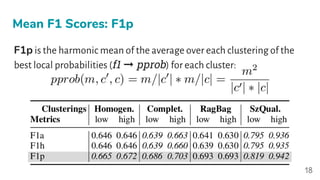
- 18. F1p is the harmonic mean of the average over each clustering of the best local probabilities (f1 ➞ pprob) for each cluster: Mean F1 Scores: F1p 18
- 19. Purpose: O(N(|C’| + |C|)) ➞ O(N) Cluster mbs # Member nodes, const cont #Members contrib, const counter # Contribs counter Counter orig # Originating cluster ctr # Raw counter, <= mbs C Indexing Technique for Mean F1 Score 19 .. ... a for a in g2.mbs: for c in cls(C.a): cc = c.counter; if cc.orig != g2: cc.ctr=0; cc.orig=g2 cc.ctr += 1 / |C.a| if ovp else 1 fmatch(cc.ctr, c.cont, g2.cont) g2 c1 c3 C’
- 20. SNAP DBLP (Nodes: 317,080 Edges: 1,049,866 Clusters: 13,477) ground-truth vs clustering by the Louvain. Evaluation on Intel Xeon E5-2620 (32 logical CPUs) @ 2.10 GHz, apps compiled using GCC 5.4 with -O3 flag. Xmeasures MF1 vs ParallelComMetric F1-Measure 20
- 21. Xmeasures MF1 vs ParallelComMetric F1-Measure Execution Time (sec) 21 Dataset Eval App xmeasures @ 1 CPU pcomet @ 32 CPUs DBLP (317K n, 13K c) 0.50 (90x speedup) 44.44 Youtube (1.13M, 16K) 0.53 (450x) 244.29 Amazon(335K, 272K) 1.84 (450x) 823.06 LiveJrn. (64M, 464K) 7.65 (> 4,100x) 31,608
- 22. Generalized Normalized Mutual Information (NMI) NMI is Mutual Information I(C’:C) normalized by the max or mean value of the unconditional entropy H of the clusterings C’, C: 22 , , GNMI [Esquivel,2012] uses a stochastic process to compute MI.
- 23. Generalized NMI Optimizations ● Dynamically evaluate the maximal number of stochastic events as: ● Apply weighed adaptive sampling instead of the fully random sampling, where only the nodes co-occurring in the clusters are sampled and weighed to discount the contribution (importance) of frequent nodes as 23
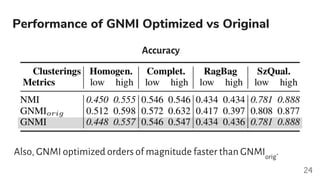
- 24. Performance of GNMI Optimized vs Original Accuracy Also, GNMI optimized orders of magnitude faster than GNMIorig . 24
- 25. Formal Constraints Satisfaction * - empirically satisfies + - satisfiers 25 *
- 26. (Soft) 𝛀 MF1 GNMI Metrics Applicability 26 O(N2 ), performs purely for the multi-resolution clusterings. Evaluates the best-matching clusters only (unfair advantage for the larger clusters). Biased to the number of clusters, non-deterministic results, the convergence is not guaranteed in the stochastic implementation. values are not affected by the number of clusters. O(N), F1p satisfiers more formal constraints than others. Highly parallelized, evaluates full matches, well-grounded theoretically.
- 29. Average F1 Score Corrected F1a can be normalized by the total or max number of clusters to be indicative for the large number of clusters: But the indicativity is lost for the small number of clusters: for |C’| = 2 ground-truth clusters and intentionally formed single cluster |C| = 1, F 1ax (C’, C) ≳ 1/3. 29