Zeus: Uber’s Highly Scalable and Distributed Shuffle as a Service
5 likes•1,818 views

The document discusses Uber's data and machine learning infrastructure, highlighting various use cases such as ETA predictions, driver/rider matches, and Uber Eats functionalities. It outlines the technology stack including Apache Spark, data analytics tools, and machine learning models employed to enhance performance and accuracy. Additionally, it mentions the implementation details of the remote shuffle service, designed to optimize data processing and enhance operational efficiency.










































Zeus: Uber’s Highly Scalable and Distributed Shuffle as a Service
- 1. Edit or delete footer text in Master ipsandella doloreium dem isciame ndaestia nessed quibus aut hiligenet ut ea debisci eturiate poresti vid min core, vercidigent. Zeus: Uber’s Highly Scalable and Distributed Shuffle as a Service Mayank Bansal, Data Infra, Uber Bo Yang, Data Infra, Uber Igniting opportunity by setting the world in motion
- 2. 15 billion trips 18M trips per day 6 continents, 69 countries and 10,000 cities 103M active monthly users 5M active drivers 22,000 employees worldwide 3,700 developers worldwide 2
- 3. Data and ML Use Cases at Uber ○ Uber Eats ○ ETAs ○ Self-Driving Vehicles ○ Customer Support ○ Driver/Rider Match ○ Personalization ○ Demand Modeling ○ Dynamic Pricing ○ Forecasting ○ Maps ○ Fraud ○ Anomaly Detection ○ Capacity Planning ○ And many more...
- 4. Data and ML at Uber - ETAs ○ ETAs are core to the Uber customer experience ○ ETAs used by myriad internal systems ○ ETA are generated by route-based algorithms ○ ML models predict the route-based ETA error ○ Uber uses the predicted error to correct the ETA ○ ETAs now dramatically more accurate
- 5. Data and ML at Uber - Driver/Rider Match ○ Optimize matchings of riders and drivers on the Uber platform ○ Predict if open rider app will make trip request
- 6. Data and ML at Uber - Eats ○ Models used for ○ Ranking of restaurants and dishes ○ Delivery times ○ Search ranking ○ 100s of ML models called to render Eats homepage
- 7. Data and ML at Uber - Self-Driving Vehicles
- 8. Edit or delete footer text in Master ipsandella doloreium dem isciame ndaestia nessed quibus aut hiligenet ut ea debisci eturiate poresti vid min core, vercidigent. Uber’s Data Stack Mobile App Events Device Telemetry Micro-Service Events Database Events 3rd Party Feeds Bulk Uploads Incremental Ingestion Kafka Realtime, Pre-Aggregated (AthenaX) Ad hoc, Interactive (Presto, Vertica) Complex, Batch (Hive) Dashboards (Summary, Dashbuilder) Ad hoc Query (QueryBuilder) Data Preparation (Piper, uWorc) BI Tools (Tableau, DSW) Stream Processing (Flink) Batch Processing (Spark, Tez, Map Reduce) Compute Fabric (YARN / Mesos + Peloton) Data Analytics Tools In-memory (Pinot, AresDB) Hot (HDFS) Warm (HDFS) Archival (Cloud) Query Engines Data Processing Engines Tiered Data Lake
- 9. Edit or delete footer text in Master ipsandella doloreium dem isciame ndaestia nessed quibus aut hiligenet ut ea debisci eturiate poresti vid min core, vercidigent. Uber’s ML Stack - Michelangelo Kafka Compute Fabric (YARN / Peloton+Mesos) Data Analytics Tools Query EnginesStream Processing (Flink) Batch Processing (Hive, Spark, Tez) Data Preparation Jupyter Notebook Spark Magic Prototype Tensorflow Training Pytorch XGBoost SparkML Feature Store Model Store Metrics Store DataLake (HDFS) Inference Realtime Prediction Service Batch Prediction Jobs
- 10. Apache Spark @Uber Image Source: www.mindproject.io
- 11. Edit or delete footer text in Master ipsandella doloreium dem isciame ndaestia nessed quibus aut hiligenet ut ea debisci eturiate poresti vid min core, vercidigent. ○ Apache Spark is the primary analytics execution engine teams at Uber use ○ At Uber, 95% batch and ML jobs run on Spark ○ We run Spark on YARN and Peloton/Mesos ○ We use external shuffle service for the shuffle data Apache Spark @ Uber 11 * Apache Hadoop,, Spark, and Mesos logos are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks. TensorFlow and the TensorFlow logo are trademarks of Google Inc. Redis is a trademark of Redis Labs Ltd. Any rights therein are reserved to Redis Labs Ltd. Any use by Uber Technologies is for referential purposes only and does not indicate any sponsorship, endorsement or affiliation between Redis and Uber Technologies.
- 12. 12 How Does Apache Spark Shuffle Service Work?
- 13. Limitations of Apache Spark Shuffle Service 13 ● SSD wearing out Issues ● Reliability ● Kubernetes dynamic allocation ● Collocation
- 14. Different Approaches 14 ● Shuffle manager to external storage ○ Synchronous writes ■ NFS ● 2X slow ■ HDFS ● 5X slow
- 15. Different Approaches 15 ● Shuffle manager to external storage ○ Semi-asynchronous writes ■ HDFS ● 4x slow
- 16. Different Approaches 16 ● Remote Shuffle Service ○ Streaming writes to HDFS ■ 1.5x slower than writing to local storage ○ Streaming Writes to Local ■ ~Same Performance like external shuffle service
- 17. Remote Shuffle Service 17 ● Remote Shuffle Service ○ Streaming Writes to Local Storage ■ Changed Mapreduce paradigm ■ Record Stream -> Shuffle Server -> Disk ■ No temporary spill files in executor side
- 18. Architecture - Remote Spark Shuffle Service 18
- 19. Deep Dive Image Source: www.mindproject.io
- 20. Design Principles 20 ● Scale out horizontally ○ Each server instance works independently ○ Avoid centralized state/storage ● Tackle network latency ○ Reduce waiting times for server response ○ Stream data ● Performance optimization ○ Most Spark Apps optimized for similar performance ○ Rely on YARN/Apache Spark retry for failure recovery
- 21. Scale Out Tackle Network Latency Performance Optimization 21
- 22. Horizontal Scalable 22 ● Spark applications share/use different shuffle servers ● No shared state among shuffle servers ● More shuffle servers to scale out
- 23. Shuffle Server Distribution 23 ● Mappers: m=4 ● Reducers: r=5 ● Shuffle Servers: s=3
- 24. Shuffle Server Distribution in General 24 ● Mappers: m ● Reducers: r ● Shuffle Servers: s ● Network Connections ○ Mappers: m*s connections ○ Reducers: r connections
- 25. Scale Out Tackle Network Latency Performance Optimization 25
- 26. Server Implementation 26 ● Use Netty ○ High performance asynchronous server framework ● Two thread groups ○ Group 1: Accept new socket connection ○ Group 2: Read socket data ○ Thread groups not block each other ● Binary network protocol ○ Efficient encoding/compression
- 27. Direct Write/Read on Disk File 27 ● Write to OS file directly ○ No application level buffering ● Zero copy ○ Transfer data from disk file to shuffle reader without user space memory ● Sequential write/read ○ No random disk IO
- 28. Client Side Compression 28 ● Shuffle client compress/decompress data ● Reduce network transport data size ● Reduce CPU usage on shuffle server ● Support client side encryption ○ Encryption key inside each application ○ Encryption key not distributed to shuffle server
- 29. Parallel Serialization and Network IO 29 ● Shuffle data serialization takes time ● Serialization in executor thread ● Network IO in another thread
- 30. Connection Pool 30 ● Socket connect latency is not trivial ● Reuse client/server connections
- 31. Scale Out Tackle Network Latency Performance Optimization 31
- 32. Asynchronous Shuffle Data Commit 32 ● Map task ○ Stream data to server ○ Not wait for response ● Server flushes (commits) data asynchronously ● Reduce task queries data availability when fetching data
- 34. Shuffle Server Discovery/Health Check 34 ● ZooKeeper as Server Registry
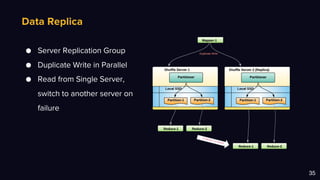
- 35. Data Replica 35 ● Server Replication Group ● Duplicate Write in Parallel ● Read from Single Server, switch to another server on failure
- 36. Local State Flush 36 ● Local state persistence in batch ○ Avoid flushing state for each map task ○ Flush when shuffle stage finishes ● Client not waiting for server side state flush
- 38. Compatible with Open Source Apache Spark 38 ● Shuffle Manager Plugin ○ spark.shuffle.manager= org.apache.spark.shuffle.RssShuffleManager ● MapStatus / MapOutputTracker ○ Embed remote shuffle service related data inside MapStatus ○ Query MapOutputTracker to retrieve needed information
- 39. Metrics/Monitoring 39 ● Uber’s open source M3 metrics library ● Important metrics ○ Network connections ○ File descriptors ○ Disk utilization
- 40. Test Strategy 40 ● Unit Test ● Stress/Random Test ● Production Query Sampling
- 41. Remote Spark Shuffle Service - Production Status 41 ● In production in last 8+ months for YARN ● Thousand’s of application running every day ● Job latencies are on par with external shuffle ● Open sourcing it soon!
- 42. Roadmap 42 ● Support all Spark workloads including HiveOnSpark ● Multi-tenancy (quota) ● Load balancing ● Integrate with incoming Spark shuffle metadata APIs
- 43. Proprietary and confidential © 2020 Uber Technologies, Inc. All rights reserved. No part of this document may be reproduced or utilized in any form or by any means, electronic or mechanical, including photocopying, recording, or by any information storage or retrieval systems, without permission in writing from Uber. This document is intended only for the use of the individual or entity to whom it is addressed and contains information that is privileged, confidential or otherwise exempt from disclosure under applicable law. All recipients of this document are notified that the information contained herein includes proprietary and confidential information of Uber, and recipient may not make use of, disseminate, or in any way disclose this document or any of the enclosed information to any person other than employees of addressee to the extent necessary for consultations with authorized personnel of Uber. 4 3 Thank you !!!