







































Spark and Spark Streaming
- 1. Spark and Spark Streaming Eric Fu 2018-Jun-04
- 2. Agenda • Spark • Resilient Distributed Datasets (RDD) • Transformations and Actions • Implementation • Spark SQL • Spark Streaming • Discretized Streams (D-Streams) • Stateful Transformations • Consistency: exactly-once • Spark Structured Streaming • System Design
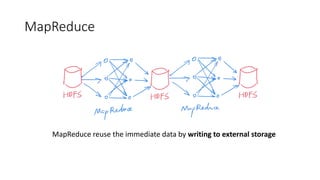
- 3. MapReduce MapReduce reuse the immediate data by writing to external storage
- 4. How to achieve fault-tolerance? • An efficient way to put data in memory and keep it persistent • Copy to external storage (costly) • Replicate to several nodes (costly) • Just recompute it (but only when data is deterministic)
- 5. Resilient Distributed Datasets (RDD) • RDD is a read-only, partitioned collection of records • RDD can only be created through deterministic operations
- 6. Resilient Distributed Datasets (RDD) lines = spark.textFile("hdfs://...") errors = lines .filter(_.startsWith("ERROR")) .filter(_.contains("HDFS")) .map(_.split('t')(3)) .collect()
- 7. Fault-tolerance • Failed partition can be recomputed • Stragglers can be moved to other nodes
- 8. Programming Interface • API similar to Java 8 Stream • Driver - Master - Worker • Driver tracks RDDs lineage • Driver send functions to Worker
- 10. Actions
- 12. PageRank in Spark Better to specify partition:
- 13. Inside RDD • Partitions • Dependencies (parents) • Iterator (constructor) • Metadata
- 14. Inside RDD (cont.) • HDFS Files • map • union • sample • join 2 kinds of dependencies
- 15. Job Execution When user runs an action ... 1. Build lineage graph (DAG) 2. Find missing partitions 3. Schedule tasks based on locality 4. Wait until completed
- 16. Spark SQL A Relational, Declarative API to Spark
- 17. Differences • DataFrame API • DataFrame = Table • Keep track of schema • An RDD of Row objects • Catalyst • SQL Optimizer • SQL with UDF
- 19. Spark Streaming From Batch to Streaming System
- 20. Existing Streaming Systems • Continuous operator model • Long-running, stateful operators • Hard to handle faults or stragglers • Hard to perform backup & recovery – replication or upstream backup
- 21. Discretized Streams (D-Streams) • Structure a streaming computation as a series of short, stateless, deterministic batch computations on small time intervals • Higher latency (100ms vs 1s) • Higher throughput (2–5x faster than Storm) • Easy to handle faults or stragglers (parallel recovery 1-2s)
- 22. Continuous model vs. D-Stream
- 23. Example • Running word count • Auto checkpoint • Fault or straggler
- 24. Programming Interface • Input • Transformation • Stateless • Or with state across intervals • Output operation
- 25. Stateful transformations • Windowing • Groups the records from a sliding window into one RDD • Incremental aggregation • Aggregate over a sliding window
- 26. Consistency Semantics • Hard to provide consistency of state across nodes in streaming system • D-Streams provide consistent "exactly-once" processing across the cluster
- 30. State Management • Asynchronous RDD Checkpointing • Lineage cutoff
- 31. Spark Structured Streaming Incremental SQL Processing
- 32. Differences • To provide exactly-once • Input sources must be replayable • Output sinks must support idempotent write • SQL and DataFrame API • User can mark a column as denoting event time • An additional continuous processing mode
- 33. "Incrementalize"
- 34. Window Tumbling Window Hopping Window Sliding Window Session Window
- 35. Watermarks • It's impossible to allow arbitrarily late data • Need to set a watermark for event time columns • Watermarks affect when stateful operators can forget old state
- 36. System Design
- 37. Architecture Master • Tracks the D-Stream lineage graph • Schedules tasks to compute new RDD partitions Worker • Receive and store partitions of RDD (input or computed) • Execute tasks
- 38. Some Details • Pipelines operators that can be grouped into a single task • Submits next timestep before the current one finished • Asynchronous checkpoints of RDDs and forgets lineage • Block store manages RDD partitions in an LRU fashion • Master recovery
- 39. Fault and Straggler • Parallel Recovery • Parallel across partitions of the RDDs in each timestep • Parallel across timesteps for independent operations • Detect stragglers (1.4× slower)
- 40. Get your hands dirty!
- 41. Thanks! Q&A
Editor's Notes
- #13: We can also write a custom Partitioner class to group pages that link to each other together (e.g., partition the URLs by domain name).
- #14: and metadata about its partitioning scheme and data placement
- #38: The system tries to place both state and tasks to maximize data locality, but this underlying flexibility makes speculation and parallel recovery possible
- #39: dropping data to disk if there is not enough memory