Postgresql search demystified
3 likes1,865 views

The document discusses the capabilities and configuration of PostgreSQL's full-text search features, including indexing, tokenization, and search algorithms. Key aspects covered include the use of GIN and GiST indexes, token analysis techniques, and various search operators for improved result relevance. Additionally, it outlines scenarios where PostgreSQL may not be the ideal solution for full-text search needs.















































Postgresql search demystified
- 1. PgConf EU 2014 presents Javier Ramirez * in * PostgreSQL Full-text search demystified @supercoco9 https://teowaki.com
- 2. The problem
- 5. One does not simply SELECT * from stuff where content ilike '%postgresql%'
- 8. Basic search features * stemmers (run, runner, running) * unaccented (josé, jose) * results highlighting * rank results by relevance
- 9. Nice to have features * partial searches * search operators (OR, AND...) * synonyms (postgres, postgresql, pgsql) * thesaurus (OS=Operating System) * fast, and space-efficient * debugging
- 10. Good News: PostgreSQL supports all the requested features
- 11. Bad News: unless you already know about search engines, the official docs are not obvious
- 12. How a search engine works * An indexing phase * A search phase
- 13. The indexing phase Convert the input text to tokens
- 14. The search phase Match the search terms to the indexed tokens
- 15. indexing in depth * choose an index format * tokenize the words * apply token analysis/filters * discard unwanted tokens
- 16. the index format * r-tree (GIST in PostgreSQL) * inverse indexes (GIN in PostgreSQL) * dynamic/distributed indexes
- 17. dynamic indexes: segmentation * sometimes the token index is segmented to allow faster updates * consolidate segments to speed-up search and account for deletions
- 18. tokenizing * parse/strip/convert format * normalize terms (unaccent, ascii, charsets, case folding, number precision..)
- 19. token analysis/filters * find synonyms * expand thesaurus * stem (maybe in different languages)
- 20. more token analysis/filters * eliminate stopwords * store word distance/frequency * store the full contents of some fields * store some fields as attributes/facets
- 21. “the index file” is really * a token file, probably segmented/distributed * some dictionary files: synonyms, thesaurus, stopwords, stems/lexems (in different languages) * word distance/frequency info * attributes/original field files * optional geospatial index * auxiliary files: word/sentence boundaries, meta-info, parser definitions, datasource definitions...
- 22. the hardest part is now over
- 23. searching in depth * tokenize/analyse * prepare operators * retrieve information * rank the results * highlight the matched parts
- 24. searching in depth: tokenize normalize, tokenize, and analyse the original search term the result would be a tokenized, stemmed, “synonymised” term, without stopwords
- 25. searching in depth: operators * partial search * logical/geospatial/range operators * in-sentence/in-paragraph/word distance * faceting/grouping
- 26. searching in depth: retrieval Go through the token index files, use the attributes and geospatial files if necessary for operators and/or grouping You might need to do this in a distributed way
- 27. searching in depth: ranking algorithm to sort the most relevant results: * field weights * word frequency/density * geospatial or timestamp ranking * ad-hoc ranking strategies
- 28. searching in depth: highlighting Mark the matching parts of the results It can be tricky/slow if you are not storing the full contents in your indexes
- 29. PostgreSQL as a full-text search engine
- 30. search features * index format configuration * partial search * word boundaries parser (not configurable) * stemmers/synonyms/thesaurus/stopwords * full-text logical operators * attributes/geo/timestamp/range (using SQL) * ranking strategies * highlighting * debugging/testing commands
- 31. indexing in postgresql you don't actually need an index to use full-text search in PostgreSQL but unless your db is very small, you want to have one Choose GIST or GIN (faster search, slower indexing, larger index size) CREATE INDEX pgweb_idx ON pgweb USING gin(to_tsvector(config_name, body));
- 32. Two new things CREATE INDEX ... USING gin(to_tsvector (config_name, body)); * to_tsvector: postgresql way of saying “tokenize” * config_name: tokenizing/analysis rule set
- 33. Configuration CREATE TEXT SEARCH CONFIGURATION public.teowaki ( COPY = pg_catalog.english );
- 34. Configuration CREATE TEXT SEARCH DICTIONARY english_ispell ( TEMPLATE = ispell, DictFile = en_us, AffFile = en_us, StopWords = spanglish ); CREATE TEXT SEARCH DICTIONARY spanish_ispell ( TEMPLATE = ispell, DictFile = es_any, AffFile = es_any, StopWords = spanish );
- 35. Configuration CREATE TEXT SEARCH DICTIONARY english_stem ( TEMPLATE = snowball, Language = english, StopWords = english ); CREATE TEXT SEARCH DICTIONARY spanish_stem ( TEMPLATE= snowball, Language = spanish, Stopwords = spanish );
- 36. Configuration Parser. Word boundaries
- 37. Configuration Assign dictionaries (in specific to generic order) ALTER TEXT SEARCH CONFIGURATION teowaki ALTER MAPPING FOR asciiword, asciihword, hword_asciipart, word, hword, hword_part WITH english_ispell, spanish_ispell, spanish_stem, unaccent, english_stem; ALTER TEXT SEARCH CONFIGURATION teowaki DROP MAPPING FOR email, url, url_path, sfloat, float;
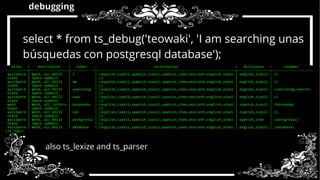
- 38. debugging select * from ts_debug('teowaki', 'I am searching unas b squedas ú con postgresql database'); also ts_lexize and ts_parser
- 39. tokenizing tokens + position (stopwords are removed, tokens are folded)
- 40. searching SELECT guid, description from wakis where to_tsvector('teowaki',description) @@ to_tsquery('teowaki','postgres');
- 41. searching SELECT guid, description from wakis where to_tsvector('teowaki',description) @@ to_tsquery('teowaki','postgres:*');
- 42. operators SELECT guid, description from wakis where to_tsvector('teowaki',description) @@ to_tsquery('teowaki','postgres | mysql');
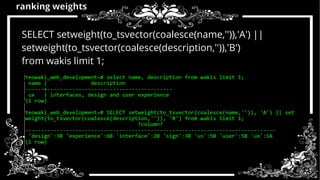
- 43. ranking weights SELECT setweight(to_tsvector(coalesce(name,'')),'A') || setweight(to_tsvector(coalesce(description,'')),'B') from wakis limit 1;
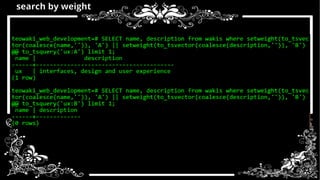
- 44. search by weight
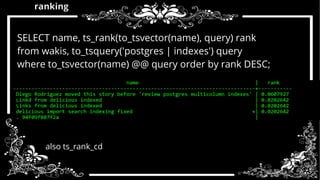
- 45. ranking SELECT name, ts_rank(to_tsvector(name), query) rank from wakis, to_tsquery('postgres | indexes') query where to_tsvector(name) @@ query order by rank DESC; also ts_rank_cd
- 46. highlighting SELECT ts_headline(name, query) from wakis, to_tsquery('teowaki', 'game|play') query where to_tsvector('teowaki', name) @@ query;
- 47. USE POSTGRESQL FOR EVERYTHING
- 48. When PostgreSQL is not good * You need to index files (PDF, Odx...) * Your index is very big (slow reindex) * You need a distributed index * You need complex tokenizers * You need advanced rankers
- 49. When PostgreSQL is not good * You want a REST API * You want sentence/ proximity/ range/ more complex operators * You want search auto completion * You want advanced features (alerts...)
- 50. But it has been perfect for us so far. Our users don't care which search engine we use, as long as it works.
- 51. PgConf EU 2014 presents Javier Ramirez * in * PostgreSQL Full-text search demystified @supercoco9 https://teowaki.com