







































![HBase – Data Model
• Cells are “versioned”
• Table rows are sorted by row key
• Region – a row range [start-key:end-key]](https://image.slidesharecdn.com/hadoopproductfamily2013-130915214424-phpapp02/85/Tcloud-Computing-Hadoop-Family-and-Ecosystem-Service-2013-Q3-41-320.jpg)
















![WordCount Example In MapReduce
public class WordCount {
public static class Map extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
context.write(word, one);
}
}
}
public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf, "wordcount");
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}](https://image.slidesharecdn.com/hadoopproductfamily2013-130915214424-phpapp02/85/Tcloud-Computing-Hadoop-Family-and-Ecosystem-Service-2013-Q3-58-320.jpg)























Tcloud Computing Hadoop Family and Ecosystem Service 2013.Q3
- 1. TCloud Computing, Inc. Hadoop Product Family and Ecosystem
- 2. Agenda • What is Big Data? • Big Data Opportunities • Hadoop – Introduction to Hadoop – Hadoop 2.0 – What’s next for Hadoop? • Hadoop ecosystem • Conclusion
- 3. What is Big Data? A set of files A database A single file
- 4. 4 V’s of Big Data http://www.datasciencecentral.com/profiles/blogs/data-veracity
- 5. Big data Expands on 4 fronts Velocity Volume Variety Veracity MB GB TB PB batch periodic near Real-Time Real-Time http://whatis.techtarget.com/definition/3Vs
- 7. Big Data Revenue by Market Segment 2012 • 1 http://wikibon.org/wiki/v/Big_Data_Vendor_Revenue_and_Market_Forecast_2012-2017
- 8. Big Data Market Forecast 2012-2017 • 1 http://wikibon.org/wiki/v/Big_Data_Vendor_Revenue_and_Market_Forecast_2012-2017
- 9. Hadoop Solutions The most common problems Hadoop can solve
- 10. Threat Analysis/Trade Surveillance • Challenge: – Detecting threats in the form of fraudulent activity or attacks • Large data volumes involved • Like looking for a needle in a haystack • Solution with Hadoop: – Parallel processing over huge datasets – Pattern recognition to identify anomalies • – i.e., threats • Typical Industry: – Security, Financial Services
- 11. Recommendation Engine • Challenge: – Using user data to predict which products to recommend • Solution with Hadoop: – Batch processing framework • Allow execution in in parallel over large datasets – Collaborative filtering • Collecting ‘taste’ information from many users • Utilizing information to predict what similar users like • Typical Industry – ISP, Advertising
- 14. Hadoop!
- 15. • Apache Hadoop project – inspired by Google's MapReduce and Google File System papers. • Open sourced, flexible and available architecture for large scale computation and data processing on a network of commodity hardware • Open Source Software + Hardware Commodity – IT Costs Reduction – inspired by
- 16. Hadoop Concepts • Distribute the data as it is initially stored in the system • Moving Computation is Cheaper than Moving Data • Individual nodes can work on data local to those nodes • Users can focus on developing applications.
- 17. Hadoop 2.0 • Hadoop 2.2.0 is expected to GA in Fall 2013 • HDFS Federation • HDFS High Availability (HA) • Hadoop YARN (MapReduce 2.0)
- 18. HDFS Federation - Limitation of Hadoop 1.0 • Scalability – Storage scales horizontally - namespace doesn’t • Performance – File system operations throughput limited by a single node • Poor isolation – All the tenants share a single namespace
- 19. HDFS Federation • Multiple independent NameNodes and Namespace Volumes in a cluster – Namespace Volume = Namespace + Block Pool • Block Storage as generic storage service – Set of blocks for a Namespace Volume is called a Block Pool – DNs store blocks for all the Namespace Volumes – no partitioning
- 20. HDFS Federation Hadoop Hadoop 2.0 http://hortonworks.com/blog/an-introduction-to-hdfs-federation/ /home//app/Hive /app/HBase
- 21. HDFS High Availability (HA) • Secondary Name Node is not Name Node • http://www.youtube.com/watch?v=hEqQMLSXQlY
- 22. HDFS High Availability (HA) https://issues.apache.org/jira/browse/HDFS-1623
- 23. Why do we need YARN • Scalability – Maximum Cluster size – 4,000 nodes – Maximum concurrent tasks – 40,000 • Single point of failure – Failure kills all queued and running jobs • Lacks support for alternate paradigms – Iterative applications implemented using MapReduce are 10x slower – Example: K-Means, PageRank
- 24. Hadoop YARN http://hortonworks.com/hadoop/yarn/
- 25. Role of YARN • Resource Manager – Per-cluster – Global resource scheduler – Hierarchical queues • Node Manager – Per-machine agent – Manages the life-cycle of container – Container resource monitoring • Application Master – Per-application – Manages application scheduling and task execution – E.g. MapReduce Application Master Job Tracker Resource Manager Application Master
- 26. Hadoop YARN architectural http://hortonworks.com/blog/apache-hadoop-yarn-background-and-an-overview/ • Container – Basic unit of allocation – Ex. Container A = 2GB, 1CPU – Fine-grained resource allocation – Replace the fixed map/reduce slots
- 27. What’s next for Hadoop? • Real-time – Apache Tez • Part of Stinger – Spark • SQL in Hadoop – Stinger • An immediate aim of 100x performance increase for Hive is more ambitious than any other effort. • Based on industry standard SQL, the Stinger Initiative improves HiveQL to deliver SQL compatibility. – Shark
- 28. What’s next for Hadoop? • Security: Data encryption – hadoop-9331: Hadoop crypto codec framework and crypto codec implementations • hadoop-9332: Crypto codec implementations for AES • hadoop-9333: Hadoop crypto codec framework based on compression codec • mapreduce-5025: Key Distribution and Management for supporting crypto codec in Map Reduce • 2013/09/28 Hadoop in Taiwan 2013 – Hadoop Security: Now and future – Session B, 16:00~16:40
- 30. Growing Hadoop Ecosystem • The term ‘Hadoop’ is taken to be the combination of HDFS and MapReduce • There are numerous other projects surrounding Hadoop – Typically referred to as the ‘Hadoop Ecosystem’ • Zookeeper • Hive and Pig • HBase • Flume • Other Ecosystem Projects – Sqoop – Oozie – Mahout
- 31. The Ecosystem is the System • Hadoop has become the kernel of the distributed operating system for Big Data • No one uses the kernel alone • A collection of projects at Apache
- 32. Relation Map MapReduce Runtime (Dist. Programming Framework) Hadoop Distributed File System (HDFS) HBase (Column NoSQL DB) Sqoop/Flume (Data integration) Oozie (Job Workflow & Scheduling) Pig/Hive (Analytical Language) Mahout (Data Mining) YARN ZooKeeper (Coordination) Tez (near real-time processing) Spark (in- memory) Shark
- 33. ZooKeeper – Coordination Framework MapReduce Runtime (Dist. Programming Framework) Hadoop Distributed File System (HDFS) HBase (Column NoSQL DB) Sqoop/Flume (Data integration) Oozie (Job Workflow & Scheduling) Pig/Hive (Analytical Language) Mahout (Data Mining) YARN ZooKeeper (Coordination) Tez (near real-time processing) Spark (in- memory) Shark
- 34. What is ZooKeeper • A centralized service for maintaining – Configuration information – Providing distributed synchronization • A set of tools to build distributed applications that can safely handle partial failures • ZooKeeper was designed to store coordination data – Status information – Configuration – Location information
- 35. Why use ZooKeeper? • Manage configuration across nodes • Implement reliable messaging • Implement redundant services • Synchronize process execution
- 36. ZooKeeper Architecture – All servers store a copy of the data (in memory) – A leader is elected at startup – 2 roles – leader and follower • Followers service clients, all updates go through leader • Update responses are sent when a majority of servers have persisted the change – HA support
- 37. HBase – Column NoSQL DB MapReduce Runtime (Dist. Programming Framework) Hadoop Distributed File System (HDFS) HBase (Column NoSQL DB) Sqoop/Flume (Data integration) Oozie (Job Workflow & Scheduling) Pig/Hive (Analytical Language) Mahout (Data Mining) YARN ZooKeeper (Coordination) Tez (near real-time processing) Spark (in- memory) Shark
- 39. I – Inspired by • Apache open source project • Inspired from Google Big Table • Non-relational, distributed database written in Java • Coordinated by Zookeeper
- 40. Row & Column Oriented
- 41. HBase – Data Model • Cells are “versioned” • Table rows are sorted by row key • Region – a row range [start-key:end-key]
- 42. When to use HBase • Need random, low latency access to the data • Application has a flexible schema where each row is slightly different – Add columns on the fly • Most of columns are NULL in each row
- 43. Flume / Sqoop – Data Integration Framework MapReduce Runtime (Dist. Programming Framework) Hadoop Distributed File System (HDFS) HBase (Column NoSQL DB) Sqoop/Flume (Data integration) Oozie (Job Workflow & Scheduling) Pig/Hive (Analytical Language) Mahout (Data Mining) YARN ZooKeeper (Coordination) Tez (near real-time processing) Spark (in- memory) Shark
- 44. What’s the problem for data collection • Data collection is currently a priori and ad hoc • A priori – decide what you want to collect ahead of time • Ad hoc – each kind of data source goes through its own collection path
- 45. (and how can it help?) • A distributed data collection service • It efficiently collecting, aggregating, and moving large amounts of data • Fault tolerant, many failover and recovery mechanism • One-stop solution for data collection of all formats
- 46. An example flow
- 47. Sqoop • Easy, parallel database import/export • What you want do? – Insert data from RDBMS to HDFS – Export data from HDFS back into RDBMS
- 48. What is Sqoop • A suite of tools that connect Hadoop and database systems • Import tables from databases into HDFS for deep analysis • Export MapReduce results back to a database for presentation to end-users • Provides the ability to import from SQL databases straight into your Hive data warehouse
- 49. How Sqoop helps • The Problem – Structured data in traditional databases cannot be easily combined with complex data stored in HDFS • Sqoop (SQL-to-Hadoop) – Easy import of data from many databases to HDFS – Generate code for use in MapReduce applications
- 50. Why Sqoop • JDBC-based implementation – Works with many popular database vendors • Auto-generation of tedious user-side code – Write MapReduce applications to work with your data, faster • Integration with Hive – Allows you to stay in a SQL-based environment
- 51. Pig / Hive – Analytical Language MapReduce Runtime (Dist. Programming Framework) Hadoop Distributed File System (HDFS) HBase (Column NoSQL DB) Sqoop/Flume (Data integration) Oozie (Job Workflow & Scheduling) Pig/Hive (Analytical Language) Mahout (Data Mining) YARN ZooKeeper (Coordination) Tez (near real-time processing) Spark (in- memory) Shark
- 52. Why Hive and Pig? • Although MapReduce is very powerful, it can also be complex to master • Many organizations have business or data analysts who are skilled at writing SQL queries, but not at writing Java code • Many organizations have programmers who are skilled at writing code in scripting languages • Hive and Pig are two projects which evolved separately to help such people analyze huge amounts of data via MapReduce – Hive was initially developed at Facebook, Pig at Yahoo!
- 53. Hive – Developed by • What is Hive? – An SQL-like interface to Hadoop • Data Warehouse infrastructure that provides data summarization and ad hoc querying on top of Hadoop – MapRuduce for execution – HDFS for storage • Hive Query Language – Basic-SQL : Select, From, Join, Group-By – Equi-Join, Muti-Table Insert, Multi-Group-By – Batch query SELECT * FROM purchases WHERE price > 100 GROUP BY storeid
- 55. Pig • A high-level scripting language (Pig Latin) • Process data one step at a time • Simple to write MapReduce program • Easy understand • Easy debug A = load ‘a.txt’ as (id, name, age, ...) B = load ‘b.txt’ as (id, address, ...) C = JOIN A BY id, B BY id;STORE C into ‘c.txt’ – Initiated by
- 56. Hive vs. Pig Hive Pig Language HiveQL (SQL-like) Pig Latin, a scripting language Schema Table definitions that are stored in a metastore A schema is optionally defined at runtime Programmait Access JDBC, ODBC PigServer
- 57. • Input • For the given sample input the map emits • the reduce just sums up the values Hello World Bye World Hello Hadoop Goodbye Hadoop < Hello, 1> < World, 1> < Bye, 1> < World, 1> < Hello, 1> < Hadoop, 1> < Goodbye, 1> < Hadoop, 1> < Bye, 1> < Goodbye, 1> < Hadoop, 2> < Hello, 2> < World, 2> WordCount Example
- 58. WordCount Example In MapReduce public class WordCount { public static class Map extends Mapper<LongWritable, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasMoreTokens()) { word.set(tokenizer.nextToken()); context.write(word, one); } } } public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> { public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } context.write(key, new IntWritable(sum)); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = new Job(conf, "wordcount"); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.setMapperClass(Map.class); job.setReducerClass(Reduce.class); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitForCompletion(true); }
- 59. WordCount Example By Pig A = LOAD 'wordcount/input' USING PigStorage as (token:chararray); B = GROUP A BY token; C = FOREACH B GENERATE group, COUNT(A) as count; DUMP C;
- 60. WordCount Example By Hive CREATE TABLE wordcount (token STRING); LOAD DATA LOCAL INPATH ’wordcount/input' OVERWRITE INTO TABLE wordcount; SELECT count(*) FROM wordcount GROUP BY token;
- 61. Spark / Shark - Analytical Language MapReduce Runtime (Dist. Programming Framework) Hadoop Distributed File System (HDFS) HBase (Column NoSQL DB) Sqoop/Flume (Data integration) Oozie (Job Workflow & Scheduling) Pig/Hive (Analytical Language) Mahout (Data Mining) YARN ZooKeeper (Coordination) Tez (near real-time processing) Spark (in- memory) Shark
- 62. Why • MapReduce is too slow • Aims to make data analytics fast — both fast to run and fast to write. • When you have the request: iterative algorithms
- 63. What is • In-memory distributed computing framework • Create by UC Berkeley AMP Lab in 2010 • Target Problem that Hadoop MR is bad at – Iterative algorithm (Machine Learning ) – Interactive data mining • More general purpose than Hadoop MR • Active contributions from ~15 companies
- 64. BDAS, the Berkeley Data Analytics Stack https://amplab.cs.berkeley.edu/software/
- 65. What Different between Hadoop and Spark Data Source Map() Data Source 2 Join() Cache()Transform http://spark.incubator.apache.org HDFS Map Reduce Map Reduce
- 66. What is Shark • A data analytic (warehouse) system that – Port of Apache Hive to run on Spark – Compatible with existing Hive data, metastores, and query(Hive, UDFs,etc) – Similar speedup of up to 40x than hive – Scale out and is fault-tolerant – Support low-latency, interactive query through in-memory computing
- 67. Shark Architecture Hive Meta Store HDFS/HBase Spark SQL Parser Query Optimizer Physical Plan Execution Cache Mgr. CLI Thrift/JDBC Driver
- 68. Oozie – Job Workflow & Scheduling MapReduce Runtime (Dist. Programming Framework) Hadoop Distributed File System (HDFS) HBase (Column NoSQL DB) Sqoop/Flume (Data integration) Oozie (Job Workflow & Scheduling) Pig/Hive (Analytical Language) Mahout (Data Mining) YARN ZooKeeper (Coordination) Tez (near real-time processing) Spark (in- memory) Shark
- 69. What is ? • A Java Web Application • Oozie is a workflow scheduler for Hadoop • Crond for Hadoop Job 1 Job 3 Job 2 Job 4 Job 5
- 70. Why • Why use Oozie instead of just cascading a jobs one after another • Major flexibility – Start, Stop, Suspend, and re-run jobs • Oozie allows you to restart from a failure – You can tell Oozie to restart a job from a specific node in the graph or to skip specific failed nodes
- 71. How it triggered • Time – Execute your workflow every 15 minutes • Time and Data – Materialize your workflow every hour, but only run them when the input data is ready. 00:15 00:30 00:45 01:00 01:00 02:00 03:00 04:00 Hadoop Input Data Exists?
- 72. Oozie use criteria • Need Launch, control, and monitor jobs from your Java Apps – Java Client API/Command Line Interface • Need control jobs from anywhere – Web Service API • Have jobs that you need to run every hour, day, week • Need receive notification when a job done – Email when a job is complete
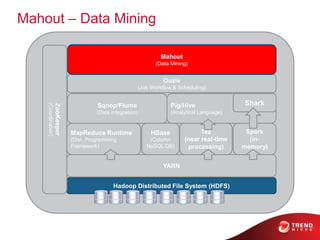
- 73. Mahout – Data Mining MapReduce Runtime (Dist. Programming Framework) Hadoop Distributed File System (HDFS) HBase (Column NoSQL DB) Sqoop/Flume (Data integration) Oozie (Job Workflow & Scheduling) Pig/Hive (Analytical Language) Mahout (Data Mining) YARN ZooKeeper (Coordination) Tez (near real-time processing) Spark (in- memory) Shark
- 74. What is • Machine-learning tool • Distributed and scalable machine learning algorithms on the Hadoop platform • Building intelligent applications easier and faster
- 75. Why • Current state of ML libraries – Lack Community – Lack Documentation and Examples – Lack Scalability – Are Research oriented
- 76. Mahout – scale • Scale to large datasets – Hadoop MapReduce implementations that scales linearly with data • Scalable to support your business case – Mahout is distributed under a commercially friendly Apache Software license • Scalable community – Vibrant, responsive and diverse
- 77. Mahout – four use cases • Mahout machine learning algorithms – Recommendation mining : takes users’ behavior and find items said specified user might like – Clustering : takes e.g. text documents and groups them based on related document topics – Classification : learns from existing categorized documents what specific category documents look like and is able to assign unlabeled documents to appropriate category – Frequent item set mining : takes a set of item groups (e.g. terms in query session, shopping cart content) and identifies, which individual items typically appear together
- 78. Use case Example • Predict what the user likes based on – His/Her historical behavior – Aggregate behavior of people similar to him
- 79. Conclusion • Big Data Opportunities – The market still growing • Hadoop 2.0 – Federation – HA – YARN • What’s next for Hadoop – Real-time query – Data encryption • What other projects are included in the Hadoop ecosystem – Different project for different purpose – Choose right tools for your needs
- 80. Recap – Hadoop Ecosystem MapReduce Runtime (Dist. Programming Framework) Hadoop Distributed File System (HDFS) HBase (Column NoSQL DB) Sqoop/Flume (Data integration) Oozie (Job Workflow & Scheduling) Pig/Hive (Analytical Language) Mahout (Data Mining) YARN ZooKeeper (Coordination) Tez (near real-time processing) Spark (in- memory) Shark
- 81. Questions?
- 82. Thank you!