KiwiPyCon 2014 - NLP with Python tutorial
Download as PPTX, PDF39 likes6,368 views

The document presents a comprehensive overview of natural language processing (NLP) using Python, authored by Alyona Medelyan, who has extensive experience in this field. It covers various aspects of NLP, including its complexities, techniques for text processing, and practical examples using libraries like NLTK and TextBlob. Additionally, it discusses keyword extraction algorithms, sentiment analysis, and text categorization methods while providing code snippets for practical application.












![“Samantha [the OS]
proves to be constantly
available, always curious
and interested, supportive
and undemanding”](https://image.slidesharecdn.com/nlptutorial-140911185437-phpapp02/85/KiwiPyCon-2014-NLP-with-Python-tutorial-13-320.jpg)








![import sys
import pocketsphinx
if __name__ == "__main__":
hmdir = "/usr/share/pocketsphinx/model/hmm/wsj1"
lmdir = "/usr/share/pocketsphinx/model/lm/wsj/wlist5o.lm.DMP"
dictd = "/usr/share/pocketsphinx/model/lm/wsj/wlist5o.dic"
wavfile = sys.argv[1]
speechRec = pocketsphinx.Decoder(hmm = hmdir, lm = lmdir, dict = dictd)
wavFile = file(wavfile,'rb')
speechRec.decode_raw(wavFile)
result = speechRec.get_hyp()
print result
Speech recognition with Python
Using CMU Sphinx
http://www.confusedcoders.com/random/speech-recognition-
in-python-with-cmu-pocketsphinx](https://image.slidesharecdn.com/nlptutorial-140911185437-phpapp02/85/KiwiPyCon-2014-NLP-with-Python-tutorial-22-320.jpg)




![Working with corpora in NLTK
>>> from nltk.corpus import movie_reviews
>>> print len(movie_reviews.fileids())
>>> print movie_reviews.categories()
>>> print movie_reviews.fileids('neg')[:10]
>>> print movie_reviews.fileids('pos')[:10]
>>> print movie_reviews.words('pos/cv000_29590.txt')
>>> print movie_reviews.raw('pos/cv000_29590.txt')
>>> print movie_reviews.sents('pos/cv000_29590.txt')](https://image.slidesharecdn.com/nlptutorial-140911185437-phpapp02/85/KiwiPyCon-2014-NLP-with-Python-tutorial-27-320.jpg)

![Getting to know text: Word frequencies
from nltk.corpus import movie_reviews
from nltk.probability import FreqDist
words = movie_reviews.words('pos/cv000_29590.txt')
freqs = FreqDist(words)
print 'Most frequent words in review’, freqs.items()[:20]
for category in movie_reviews.categories():
print 'Category', category
all_words = movie_reviews.words(categories=category)
all_words_by_frequency = FreqDist(all_words)
print all_words_by_frequency.items()[:20]](https://image.slidesharecdn.com/nlptutorial-140911185437-phpapp02/85/KiwiPyCon-2014-NLP-with-Python-tutorial-29-320.jpg)


![Stopword removal with NLTK
from nltk.corpus import movie_reviews
from nltk.corpus import stopwords
stop = stopwords.words('english')
words = movie_reviews.words('pos/cv000_29590.txt')
no_stops = [word for word in words if word not in stop]](https://image.slidesharecdn.com/nlptutorial-140911185437-phpapp02/85/KiwiPyCon-2014-NLP-with-Python-tutorial-32-320.jpg)
![NLTK Stopwords: Before & After
['films', 'adapted', 'from', 'comic', 'books',
'have', 'had', 'plenty', 'of', 'success', ',',
'whether', 'they', "'", 're', 'about', 'superheroes',
'(', 'batman', ',']
['films', 'adapted', 'comic', 'books', 'plenty',
'success', ',', 'whether', "'", 're', 'superheroes',
'(', 'batman', ',’]](https://image.slidesharecdn.com/nlptutorial-140911185437-phpapp02/85/KiwiPyCon-2014-NLP-with-Python-tutorial-33-320.jpg)
![Part of speech tagging & filtering
import nltk
from nltk.corpus import movie_reviews
from nltk.probability import FreqDist
words = movie_reviews.words('pos/cv000_29590.txt')
pos = nltk.pos_tag(words)
filtered_words = [x[0] for x in pos if x[1] in ('NN', 'JJ')]
print FreqDist(filtered_words).items()[:20]](https://image.slidesharecdn.com/nlptutorial-140911185437-phpapp02/85/KiwiPyCon-2014-NLP-with-Python-tutorial-34-320.jpg)

![Ngram extraction with NLTK
my_ngrams = []
for n in range(2, 5):
for gram in ngrams(words, n):
if acceptable(gram[0])
and acceptable(gram[-1])
and has_no_boundaries(gram):
phrase = ' '.join(gram)
my_ngrams.append(phrase)
[("' s", 11), ("' t", 10), (', but', 6), ("don '", 5), ("don ' t", 5), ('from hell', 5)
[('comic book', 2), ('jack the ripper', 2), ('moore and campbell', 2), ('say moore', 2),](https://image.slidesharecdn.com/nlptutorial-140911185437-phpapp02/85/KiwiPyCon-2014-NLP-with-Python-tutorial-37-320.jpg)

![TFxIDF with Gensim
from nltk.corpus import movie_reviews
from gensim import corpora, models
texts = []
for fileid in movie_reviews.fileids():
words = movie_reviews.words(fileid)
texts.append(words)
dictionary = corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
tfidf = models.TfidfModel(corpus)
for word in ['film', 'movie', 'comedy', 'violence', 'jolie']:
id = dictionary.token2id.get(word)
print word, id, tfidf.idfs[id]](https://image.slidesharecdn.com/nlptutorial-140911185437-phpapp02/85/KiwiPyCon-2014-NLP-with-Python-tutorial-39-320.jpg)



![Candidates extraction in Python
def get_candidates(words, stop):
filtered_words = [word for word in words
if word not in stop
and word[0].isalpha()]
text_ngrams = get_ngrams(words, stop)
return filtered_words + text_ngrams](https://image.slidesharecdn.com/nlptutorial-140911185437-phpapp02/85/KiwiPyCon-2014-NLP-with-Python-tutorial-43-320.jpg)
![Candidate scoring in Python
def score_candidates(candidates, dictionary, tfidf):
scores = {}
freqs = FreqDist(candidates)
for word in set(candidates):
tf = float(frequencies[word]) / len(freqs)
id = dictionary.token2id.get(word)
if id:
idf = tfidf.idfs[id]
else:
idf = 0
scores[word] = tf*idf
return sorted(scores.iteritems(),
key=operator.itemgetter(1), reverse = True)](https://image.slidesharecdn.com/nlptutorial-140911185437-phpapp02/85/KiwiPyCon-2014-NLP-with-Python-tutorial-44-320.jpg)



![Insights – Step 1
from nltk.corpus import movie_reviews
from nltk.probability import FreqDist
from basics_applied import keyword_extractor
candidate_extractor = keyword_extractor.CandidateExtractor()
texts = []
texts_ids = {}
count = 0
for fileid in movie_reviews.fileids():
words = candidate_extractor.run(movie_reviews.words(fileid))
texts.append(words)
texts_ids[fileid] = count
count += 1](https://image.slidesharecdn.com/nlptutorial-140911185437-phpapp02/85/KiwiPyCon-2014-NLP-with-Python-tutorial-48-320.jpg)
![Insights – Step 2
for category in movie_reviews.categories():
print 'Category', category
category_keywords = []
for fileid in movie_reviews.fileids(categories=category):
count = texts_ids[fileid]
candidates = texts[count]
keywords = candidate_scorer.run(candidates)[:20]
for keyword in keywords:
category_keywords.append(keyword[0])
if ' ' in keyword[0]:
category_keywords.append(keyword[0])
cat_keywords_by_frequency = FreqDist(category_keywords)
print cat_keywords_by_frequency.items()[:50]](https://image.slidesharecdn.com/nlptutorial-140911185437-phpapp02/85/KiwiPyCon-2014-NLP-with-Python-tutorial-49-320.jpg)




![Text Classification with Python
documents = [(list(movie_reviews.words(fileid)), category)
for category in movie_reviews.categories()
for fileid in movie_reviews.fileids(category)]
random.shuffle(documents)
all_words = nltk.FreqDist(w.lower() for w in movie_reviews.words())
word_features = all_words.keys()[:2000]
# document_features: for word in word_features:
# features['contains(%s)' % word] = (word in doc_words)
featuresets = [(document_features(d), c) for (d,c) in documents]
train_set, test_set = featuresets[1000:], featuresets[:1000]
classifier = nltk.NaiveBayesClassifier.train(train_set)
print(nltk.classify.accuracy(classifier, test_set))](https://image.slidesharecdn.com/nlptutorial-140911185437-phpapp02/85/KiwiPyCon-2014-NLP-with-Python-tutorial-54-320.jpg)
![Classify new reviews using NLTK
# from http://www.imdb.com/title/tt2209764/reviews?ref_=tt_urv
transcendence = ['../data/transcendence_1star.txt',
'../data/transcendence_5star.txt',
'../data/transcendence_8star.txt',
'../data/transcendence_great.txt']
classifier = nltk.NaiveBayesClassifier.train(featuresets)
for review in transcendence:
f = open(review)
raw = f.read()
document = word_tokenize(raw)
features = document_features(document)
print review, classifier.classify(features)](https://image.slidesharecdn.com/nlptutorial-140911185437-phpapp02/85/KiwiPyCon-2014-NLP-with-Python-tutorial-55-320.jpg)




![Insights through
Topic Modeling with GenSim
candidate_extractor = basics_applied.keyword_extractor.CandidateExtractor()
for category in movie_reviews.categories():
texts = []
for fileid in movie_reviews.fileids(category):
words = movie_reviews.words(fileid)
clean_words = texts.append(candidate_extractor.run(words, 2))
dictionary = corpora.Dictionary(texts)
dictionary.filter_extremes(no_below=10, no_above=0.1, keep_n=10000)
corpus = [dictionary.doc2bow(text) for text in texts]
print 'Category', category
print 'LDA'
lda = models.ldamodel.LdaModel(corpus, id2word=dictionary)
print 'HDP'
model = models.hdpmodel.HdpModel(corpus, id2word=dictionary)](https://image.slidesharecdn.com/nlptutorial-140911185437-phpapp02/85/KiwiPyCon-2014-NLP-with-Python-tutorial-60-320.jpg)










KiwiPyCon 2014 - NLP with Python tutorial
- 1. Understanding human language with Python Alyona Medelyan
- 2. Who am I? Alyona Medelyan aka @zelandiya ▪ In Natural Language Processing since 2000 ▪ PhD in NLP & Machine Learning from Waikato ▪ Author of the state-of-the-art keyword extraction algorithm Maui ▪ Author of the most-cited 2009 journal survey “Mining Meaning with Wikipedia” ▪ Past: Chief Research Officer at Pingar ▪ Now: Founder of Entopix, NLP consultancy & software development
- 3. Pre-tutorial survey results Programming Python Beginers Experts 85% no experience with NLP, general interest
- 4. Agenda State of NLP Recap on fiction vs reality: Are we there yet? NLP Complexities Why is understanding language so complex? NLP using Python Learning the basics, applying them, expanding into further topics Other NLP areas And what’s coming next
- 5. State of NLP Fiction versus Reality
- 6. He (KITT) “always had an ego that was easy to bruise and displayed a very sensitive, but kind and dryly humorous personality.” - Wikipedia
- 7. Android Auto: “hands-free operation through voice commands will be emphasized to ensure safe driving”
- 8. “by putting this into one's ear one can instantly understand anything said in any language” (Hitchhiker Wiki)
- 9. WordLense: “augmented reality translation”
- 10. The LCARS (or simply library computer) … used sophisticated artificial intelligence routines to understand and execute vocal natural language commands (From Memory Alpha Wiki)
- 11. Let’s try out Google
- 12. It doesn’t always work… (the person searched for “Steve Jobs”)
- 13. “Samantha [the OS] proves to be constantly available, always curious and interested, supportive and undemanding”
- 14. Siri doesn’t seem to be as “available”
- 15. NLP Complexities What is understanding language so complex?
- 17. Sentence detection complexities Last week's GDP figures, which were 0.8% for the March quarter (average forecast was 0.4%) and included a revision of the December quarter figures from 0.2% to 0.5%... That takes away the rationale for the OCR to remain at stimulatory levels.It is currently at 2.5%. Also, in fighting inflation, Dr. Bollard has one rather tricky ally - the exchange rate, which hit a record 85USc last week in N.Z. Running at that level, the currency is keeping imported inflation at low levels.
- 18. Word segmentation complexities ▪ 广大发展中国家一致支持这个目标,并提出了各自的期望细节。 ▪ 广大发展中国家一致支持这个目标,并提出了各自的期望细节。 ▪ The first hot dogs were sold by Charles Feltman on Coney Island in 1870. ▪ The first hot dogs were sold by Charles Feltman on Coney Island in 1870.
- 19. Disambiguation complexities Flying planes can be dangerous
- 20. Sentiment complexities from: http://www.sentic.net/tutorial/
- 21. NLP using Python Learning the basics, applying them, expanding into further topics
- 22. import sys import pocketsphinx if __name__ == "__main__": hmdir = "/usr/share/pocketsphinx/model/hmm/wsj1" lmdir = "/usr/share/pocketsphinx/model/lm/wsj/wlist5o.lm.DMP" dictd = "/usr/share/pocketsphinx/model/lm/wsj/wlist5o.dic" wavfile = sys.argv[1] speechRec = pocketsphinx.Decoder(hmm = hmdir, lm = lmdir, dict = dictd) wavFile = file(wavfile,'rb') speechRec.decode_raw(wavFile) result = speechRec.get_hyp() print result Speech recognition with Python Using CMU Sphinx http://www.confusedcoders.com/random/speech-recognition- in-python-with-cmu-pocketsphinx
- 23. text text text text text text text text text text text text text text text text text text sentiment keywords tags genre categories taxonomy terms entities names patterns biochemical … entities text text text text text text text text text text text text text text text text text text What can we do with text?
- 24. text text text text text text text text text text text text text text text text text text sentiment keywords tags genre categories taxonomy terms entities names patterns biochemical … entities text text text text text text text text text text text text text text text text text text What can we do with text? practical part of this tutorial
- 25. Introducing NLTK – Python platform for NLP
- 26. Setting up Clone or Download ZIP: https://github.com/zelandiya/KiwiPyCon-NLP-tutorial
- 27. Working with corpora in NLTK >>> from nltk.corpus import movie_reviews >>> print len(movie_reviews.fileids()) >>> print movie_reviews.categories() >>> print movie_reviews.fileids('neg')[:10] >>> print movie_reviews.fileids('pos')[:10] >>> print movie_reviews.words('pos/cv000_29590.txt') >>> print movie_reviews.raw('pos/cv000_29590.txt') >>> print movie_reviews.sents('pos/cv000_29590.txt')
- 28. NLTK Corpus – basic functionality
- 29. Getting to know text: Word frequencies from nltk.corpus import movie_reviews from nltk.probability import FreqDist words = movie_reviews.words('pos/cv000_29590.txt') freqs = FreqDist(words) print 'Most frequent words in review’, freqs.items()[:20] for category in movie_reviews.categories(): print 'Category', category all_words = movie_reviews.words(categories=category) all_words_by_frequency = FreqDist(all_words) print all_words_by_frequency.items()[:20]
- 30. Output of “frequent words” Most frequent words in review [('the', 46), (',', 43), ("'", 25), ('.', 23), ('and', 21), ... Category neg [(',', 35269), ('the', 35058), ('.', 32162), ('a', 17910), ... Category pos [(',', 42448), ('the', 41471), ('.', 33714), ('a', 20196), ...
- 31. How to get to the core words? even the acting in from hell is solid , with the dreamy depp turning in a typically strong performance i think that from hell has a pretty solid acting, especially with the dreamy depp turning in a strong performance as he usually does * Remove Stopwords! * “from hell” is the title of the movie, using just stopwords will not be sufficient to process this example correctly
- 32. Stopword removal with NLTK from nltk.corpus import movie_reviews from nltk.corpus import stopwords stop = stopwords.words('english') words = movie_reviews.words('pos/cv000_29590.txt') no_stops = [word for word in words if word not in stop]
- 33. NLTK Stopwords: Before & After ['films', 'adapted', 'from', 'comic', 'books', 'have', 'had', 'plenty', 'of', 'success', ',', 'whether', 'they', "'", 're', 'about', 'superheroes', '(', 'batman', ','] ['films', 'adapted', 'comic', 'books', 'plenty', 'success', ',', 'whether', "'", 're', 'superheroes', '(', 'batman', ',’]
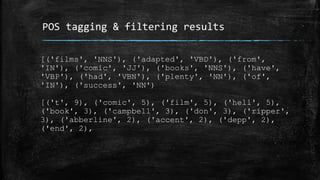
- 34. Part of speech tagging & filtering import nltk from nltk.corpus import movie_reviews from nltk.probability import FreqDist words = movie_reviews.words('pos/cv000_29590.txt') pos = nltk.pos_tag(words) filtered_words = [x[0] for x in pos if x[1] in ('NN', 'JJ')] print FreqDist(filtered_words).items()[:20]
- 35. POS tagging & filtering results [('films', 'NNS'), ('adapted', 'VBD'), ('from', 'IN'), ('comic', 'JJ'), ('books', 'NNS'), ('have', 'VBP'), ('had', 'VBN'), ('plenty', 'NN'), ('of', 'IN'), ('success', 'NN') [('t', 9), ('comic', 5), ('film', 5), ('hell', 5), ('book', 3), ('campbell', 3), ('don', 3), ('ripper', 3), ('abberline', 2), ('accent', 2), ('depp', 2), ('end', 2),
- 36. From Single to Multi-Word Phrases NEJM usually has the highest impact factor of the journals of clinical medicine. ignore stopwords highest, highest impact, highest impact factor Option 1. Ngrams Option 2. Chunking / POS patterns from http://www.nltk.org/book/ch07.html#chap-chunk
- 37. Ngram extraction with NLTK my_ngrams = [] for n in range(2, 5): for gram in ngrams(words, n): if acceptable(gram[0]) and acceptable(gram[-1]) and has_no_boundaries(gram): phrase = ' '.join(gram) my_ngrams.append(phrase) [("' s", 11), ("' t", 10), (', but', 6), ("don '", 5), ("don ' t", 5), ('from hell', 5) [('comic book', 2), ('jack the ripper', 2), ('moore and campbell', 2), ('say moore', 2),
- 39. TFxIDF with Gensim from nltk.corpus import movie_reviews from gensim import corpora, models texts = [] for fileid in movie_reviews.fileids(): words = movie_reviews.words(fileid) texts.append(words) dictionary = corpora.Dictionary(texts) corpus = [dictionary.doc2bow(text) for text in texts] tfidf = models.TfidfModel(corpus) for word in ['film', 'movie', 'comedy', 'violence', 'jolie']: id = dictionary.token2id.get(word) print word, id, tfidf.idfs[id]
- 40. TFxIDF with Gensim: Results film 124 0.190174003903 movie 207 0.364013496254 comedy 653 1.98564470702 violence 1382 3.2108967825 jolie 9418 6.96578428466
- 41. NLP using Python Learning the basics, applying them, expanding into further topics
- 42. How a keyword extraction algorithm works Document Candidates Properties Scoring Keywords Slide window Break at stopwords & punctuation Normalize Map to vocabulary (optional) Disambiguate (optional) Calculate: Frequency of occurrences Position in the document Phrase length Similarity to other candidates Prominence in this particular text Part of speech pattern Is it a popular keyword? Heuristic formula that combines most powerful properties OR Supervised machine learning that learns the importance of properties from manually assigned keywords
- 43. Candidates extraction in Python def get_candidates(words, stop): filtered_words = [word for word in words if word not in stop and word[0].isalpha()] text_ngrams = get_ngrams(words, stop) return filtered_words + text_ngrams
- 44. Candidate scoring in Python def score_candidates(candidates, dictionary, tfidf): scores = {} freqs = FreqDist(candidates) for word in set(candidates): tf = float(frequencies[word]) / len(freqs) id = dictionary.token2id.get(word) if id: idf = tfidf.idfs[id] else: idf = 0 scores[word] = tf*idf return sorted(scores.iteritems(), key=operator.itemgetter(1), reverse = True)
- 45. Test keywords extractor …four of the biggest directors in hollywood : quentin tarantino , robert rodriguez , … were all directing one big film with a big and popular cast ...the second room ( jennifer beals ) was better , but lacking in plot ... the bumbling and mumbling bellboy , and he ruins every joke in the film … bellboy jennifer beals four rooms beals rooms tarantino madonna antonio banderas valeria golino
- 46. Analysis of the results neg/cv480_21195.txt fight club, club, fight, se7en and the game, inter - office, inter - office politics, tyler, office politics, politics, woven, inter, befuddled neg/cv235_10704.txt babysitter, goal of the babysitter, thug, boyfriend, goal, fails, fantasizes, dream sequences, silverstone, dream neg/cv248_15672.txt vampires, vampire, rude, suggestion, regressive movie neg/cv136_12384.txt lost in space, robinson, robinsons, story changes, cartoony • Remove sub-phrases in favour of higher ranked ones • Score higher Adjectives & Adverb using Part of Speech tagging • Add stemming • …
- 47. Getting insights from text! Which actors, directors, movie plots and film qualities make a successful movie? 1. Apply candidate extraction on each review (to initialize TFxIDF scorer) 2. Extract common keywords from positive and negative reviews
- 48. Insights – Step 1 from nltk.corpus import movie_reviews from nltk.probability import FreqDist from basics_applied import keyword_extractor candidate_extractor = keyword_extractor.CandidateExtractor() texts = [] texts_ids = {} count = 0 for fileid in movie_reviews.fileids(): words = candidate_extractor.run(movie_reviews.words(fileid)) texts.append(words) texts_ids[fileid] = count count += 1
- 49. Insights – Step 2 for category in movie_reviews.categories(): print 'Category', category category_keywords = [] for fileid in movie_reviews.fileids(categories=category): count = texts_ids[fileid] candidates = texts[count] keywords = candidate_scorer.run(candidates)[:20] for keyword in keywords: category_keywords.append(keyword[0]) if ' ' in keyword[0]: category_keywords.append(keyword[0]) cat_keywords_by_frequency = FreqDist(category_keywords) print cat_keywords_by_frequency.items()[:50]
- 50. Our insights Negative Positive van damme 16 zeta - jones 16 smith 15 batman 14 de palma 14 eddie murphy 14 killer 14 tommy lee jones 14 wild west 14 mars 13 murphy 13 ship 13 space 13 brothers 12 de bont 12 ... star wars 26 disney 23 war 23 de niro 22 jackie 21 alien 20 jackie chan 20 private ryan 20 truman show 20 ben stiller 18 cameron 18 science fiction 18 cameron diaz 16 fiction 16 jack 16 ...
- 51. NLP using Python Learning the basics, applying them, expanding into further topics
- 52. Text Categorization Entertainment TVNZ: “Obama and Hangover star trade insults in interview” Politics textanddatamining.blogspot.co.nz/2011/07/svm-classification-intuitive.html
- 53. Categorization vs Keyword Extraction source of terminology number of topics any document vocabulary tagging keyword assignment keyword extraction term assignment very few main topics only domain-relevant all possible text categorization terminology extraction topic modeling full-text indexing
- 54. Text Classification with Python documents = [(list(movie_reviews.words(fileid)), category) for category in movie_reviews.categories() for fileid in movie_reviews.fileids(category)] random.shuffle(documents) all_words = nltk.FreqDist(w.lower() for w in movie_reviews.words()) word_features = all_words.keys()[:2000] # document_features: for word in word_features: # features['contains(%s)' % word] = (word in doc_words) featuresets = [(document_features(d), c) for (d,c) in documents] train_set, test_set = featuresets[1000:], featuresets[:1000] classifier = nltk.NaiveBayesClassifier.train(train_set) print(nltk.classify.accuracy(classifier, test_set))
- 55. Classify new reviews using NLTK # from http://www.imdb.com/title/tt2209764/reviews?ref_=tt_urv transcendence = ['../data/transcendence_1star.txt', '../data/transcendence_5star.txt', '../data/transcendence_8star.txt', '../data/transcendence_great.txt'] classifier = nltk.NaiveBayesClassifier.train(featuresets) for review in transcendence: f = open(review) raw = f.read() document = word_tokenize(raw) features = document_features(document) print review, classifier.classify(features)
- 56. Sentiment analysis with TextBlob from textblob import TextBlob from textblob.sentiments import NaiveBayesAnalyzer blob = TextBlob("I love this library", analyzer=NaiveBayesAnalyzer()) print blob.sentiment Sentiment(classification='pos', p_pos=0.7996209910191279, p_neg=0.2003790089808724) blob = TextBlob("I love this library") print blob.sentiment Sentiment(polarity=0.5, subjectivity=0.6)
- 57. Sentiment Categorization with Text Blob for review in transcendence: f = open(review) raw = f.read() blob = TextBlob(raw) sentiment = blob.sentiment if sentiment.polarity > 0.20: print review, 'pos', round(sentiment.polarity, 3), round(sentiment.subjectivity, 3) else: print review, 'neg', round(sentiment.polarity, 3), round(sentiment.subjectivity, 3) ../data/transcendence_1star.txt neg 0.017 0.502 ../data/transcendence_5star.txt neg 0.087 0.51 ../data/transcendence_8star.txt pos 0.257 0.494 ../data/transcendence_great.txt pos 0.304 0.528
- 58. Sentiment analysis: Aspects http://www.sentic.net/tutorial/
- 60. Insights through Topic Modeling with GenSim candidate_extractor = basics_applied.keyword_extractor.CandidateExtractor() for category in movie_reviews.categories(): texts = [] for fileid in movie_reviews.fileids(category): words = movie_reviews.words(fileid) clean_words = texts.append(candidate_extractor.run(words, 2)) dictionary = corpora.Dictionary(texts) dictionary.filter_extremes(no_below=10, no_above=0.1, keep_n=10000) corpus = [dictionary.doc2bow(text) for text in texts] print 'Category', category print 'LDA' lda = models.ldamodel.LdaModel(corpus, id2word=dictionary) print 'HDP' model = models.hdpmodel.HdpModel(corpus, id2word=dictionary)
- 61. Insights Negative topic 0: acting ability + battle scenes + pretty much + mission to mars + natasha henstridge + live action + ve never + freddie prinze jr topic 1: bad acting + naked gun + lead role + close - ups + antonio banderas + johnny depp + nothing else + kind of movie + wild wild west topic 2: salma hayek + woody allen + pulp fiction + next time + make sense + make a movie + target audience + opening sequence topic 3: subject matter + horror movie + first one + anyone else + throughout the movie + granger movie + end credits + never seen topic 4: million dollars + ll see + deep impact + de palma + watching the film + granger movie gauge + didn ' t like + makes no sense Positive topic 0: martin scorsese + soap opera + fbi agent + old man + first thing + doesn ' t make + entertaining film + first - time + doesn ' t know topic 1: stanley kubrick + matt dillon + film i ' ve + time period + film like + last two + computer animation + men and women + whole film topic 2: action film + good and evil + star trek + usual suspects + soon becomes + written and directed + time period + new york + first movie topic 3: julianne moore + feature film + tom cruise + doesn ' t want + real people + much better + action sequences + see the movie topic 4: re looking + soap opera + austin powers + edward norton + entertaining film + well enough + old - fashioned + animated feature
- 62. LDA: Practical application Sweaty Horse Blanket: Processing the Natural Language of Beer by Ben Fields
- 63. 1. Keyword extraction 2. TFxIDF scoring 3. LDA
- 64. Other NLP areas What’s coming next?
- 65. From Strings to Concepts Precc is a new compiler-compiler tool that is much more versatile than yacc. most likely less likely unlikely ✓
- 66. From Concepts to Facts
- 67. Applying the Semantic Web technology ▪ Show all politicians, their birth date and gender, mentioned in the document collection and in which documents they appear Al Gore 31-03-1948 male Al Green 01-09-1947 male Alan Hunt 09-10-1927 male Alberto Fujimori 28-07-1938 male Barack Obama 04-08-1961 male Benazir Bhutto 21-06-1953 female … Semantic SPARQL Query select distinct ?name ?birth ?gender where { graph <http://some.url/> …
- 68. Parsing … Jack Ruby, who killed J.F.Kennedy's assassin Lee Harvey Oswald. … /m/0d3k14 /m/044sb /m/0d3k14 Sentiment 0% Positive 30% Neutral 70% Negative Freebase
- 69. What’s next? Vs.
- 70. Conclusions: Understanding human language with Python State of NLP Recap on fiction vs reality: Are we there yet? NLP Complexities Why is understanding language so complex? NLP using Python NLTK, Gensim & TextBlob Other NLP areas And what’s coming next Try also: scikit-learn.org/stable/ Pattern clips.ua.ac.be/pages/pattern PyNLPl github.com/proycon/pynlpl
Editor's Notes
- #7: The "brain" of KITT is the Knight 2000 microprocessor which is the centre of a "self-aware"cybernetic logic module that allowed KITT to think, learn, communicate and interact with humans. He always had an ego that was easy to bruise and displayed a very sensitive, but kind and dryly humorous personality. (from Wikipedia)