![]()
RAG retrieves documents. Agents need to retrieve beliefs.
npm install -g bellamem, thenbellamem install && bellamem daemon start. Use/bellain any Claude Code session. The daemon auto-saves your graph every 5 minutes and serves a localhost web UI with a session trace replay view athttp://localhost:7878.
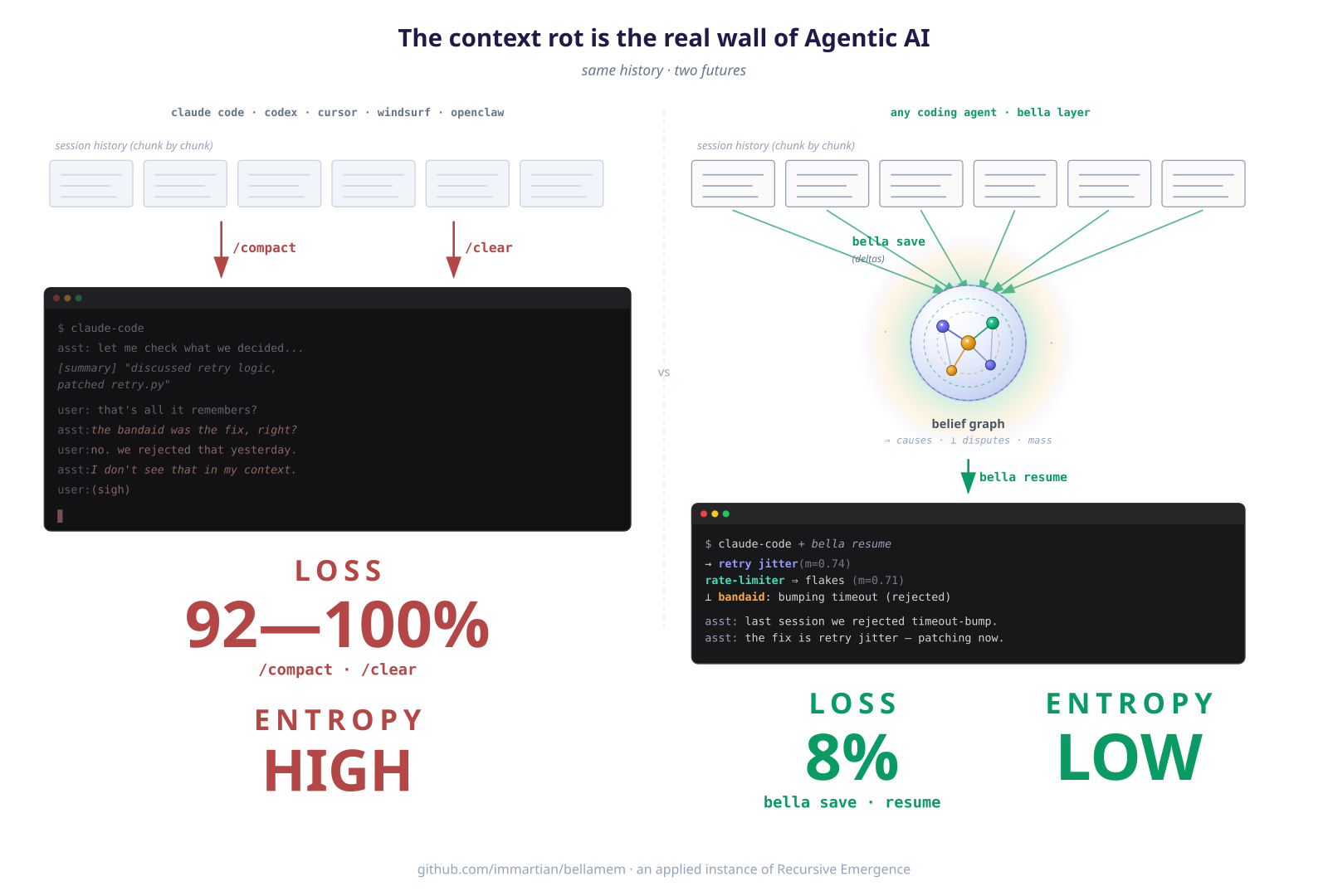
Your AI agent is like a brilliant intern with amnesia. Every morning you re-explain the project. Every afternoon it re-introduces the bug you fixed yesterday. It smiles and nods and produces confidently wrong output. Fluent, agreeable, and fundamentally untrustworthy.
Loses continuity. Today's session suggests the exact bandaid you rejected yesterday. Yesterday doesn't exist.
Hits the wall. /compact and /clear evaporate the specifics —
rejected approaches, causal chains, small invariants that took ten
messages to earn.
Confabulates with conviction. When it forgets, it doesn't ask to be reminded. It re-asserts the wrong approach with full confidence, and you're the one who has to catch it every time.
One root cause: agents only have working memory. The context window is the memory. When a turn falls out, it's gone — and the agent carries on unaware, filling the gap with plausible defaults. You can't guardrail a system that doesn't own its own beliefs.
Bella is the long-term memory layer. It extracts the structure
of every conversation — decisions, rejected approaches, causes,
self-observations — into a belief hypergraph that survives /clear,
new sessions, and new days. When tomorrow's session asks about the
flaky test, it loads what yesterday decided, what yesterday rejected,
and why.
Measured across 15 real Claude Code projects on a developer's machine, Bella compresses the conversation portion of the context window by median 17.6× (range 3.6×–90×). The biggest sample (132k raw tokens) hit 90× — see the production curve.
A real debugging session — twenty turns of dead-ends, side-questions,
acknowledgments, and the actual fix at the end. Left column is what
the context window holds. Right column is what Bella extracts
alongside it — and what survives after /clear.
| Flat session — what the context window holds | Bella hypergraph — what survives |
|---|---|
|
|
|
~220 tokens · 20 turns · ordered by time · dies at |
~50 tokens · 4 beliefs · ordered by evidence mass · persists |
Same information content, different geometry. The left column lets an agent reconstruct what was said. The right column lets it reconstruct what was decided, what was rejected, and what caused what — in far fewer tokens, and across the session boundaries where the left column can't go.
And the four items on the right are exactly the ones the agent would otherwise forget, re-suggest, or confabulate about tomorrow: a ratified decision (mass earned from two voices), a causal chain (the why), a dispute (the rejected bandaid, which Bella's edit guard will block if the agent tries it again), and a self-observation about its own reasoning pattern.
Every concept in Bella is classified along two orthogonal axes. The axes aren't decorative — they drive retrieval, decay, and dispute handling differently. A normative decision about testing style doesn't decay the way an ephemeral observation about yesterday's build does.
Class — where does it come from and how is it used?
| class | shape | meaning |
|---|---|---|
| invariant | hexagon | time-invariant principles and facts — they don't decay |
| decision | diamond | a commitment that constrains future action — revisable |
| observation | ellipse | a single empirical record — a snapshot |
| ephemeral | rounded square | pinned for short-term use, has an open→consumed/retracted/stale lifecycle |
Nature — what kind of claim is this?
| nature | color | meaning |
|---|---|---|
| metaphysical | amber | what the system IS — self-model, architectural facts |
| normative | blue | what we commit to — rules, preferences, policies |
| factual | green | measurable, checkable facts about the world |
The 12 cells are a full typology — invariant × metaphysical is the
deepest bedrock ("the graph is append-only"), ephemeral × factual is
throwaway ("yesterday's CI was red"). Mass accumulates on every cell
the same way (Jaynes log-odds from each ratifying voice), but the
retrieval guard, the decay curve, and the dispute resolution read
each cell differently.
You can see the full ontology rendered live on your own graph:
bellamem serve # localhost:7878, graph viewShape encodes class, color encodes nature, node size encodes
mass. The D3 force-directed graph view with session coloring and
concept drawer is available at http://localhost:7878/p/<project>/graph.
npm install -g bellamem # one binary: bellamem (+ bella alias)
bellamem install # writes /bella slash command for Claude Code
bellamem daemon start # web UI + auto-save loop, one processThat's it. Three commands, then /bella works in every Claude Code
session on your machine and http://localhost:7878 shows the
multi-project dashboard.
npx (no global install):
npx bellamem install # one-time slash command write
npx bellamem save # on-demand save (no daemon)From source:
git clone https://github.com/immartian/bellamem
cd bellamem/packages/bellamem
npm install && npm run build
bellamem installbellamem install writes:
~/.claude/commands/bella.md— the/bellaClaude Code slash command. (Removes the legacy/bellamemcommand if present.)~/.config/bellamem/.env— a template withOPENAI_API_KEYcommented out. Fill it in to enable ingest.
Bella needs an OpenAI key for embeddings and LLM extraction. Three places it looks, in precedence order:
- Shell environment —
export OPENAI_API_KEY=sk-...in~/.bashrcor equivalent. Covers interactive CLI in any project. - Project
.env— at your git repo root. Per-project override when different projects need different keys. Gitignored. - User config —
~/.config/bellamem/.envon Linux, the native equivalent on macOS and Windows (env-paths-resolved). Recommended default: set the key once here, and both the CLI and the background daemon pick it up automatically.
First-time setup for most users:
mkdir -p ~/.config/bellamem
echo 'OPENAI_API_KEY=sk-...' > ~/.config/bellamem/.env
chmod 600 ~/.config/bellamem/.envProject .env.example is still provided for projects that want
explicit per-project config.
Bella uses gpt-4o-mini for per-turn classification and
text-embedding-3-small for topic embeddings. Both are cached
by content hash — you pay once per unique turn or topic, never
on re-runs. Caching is what makes the cost bounded.
Measured from this repo's dogfood loop (running bellamem save
every 5 minutes on all new turns across ~6 days of active
development): ~$1.20 cumulative across ~3,350 classified turns.
That's about 3¢ per 100-turn session, with embeddings
contributing rounding-error ($0.0003 for 2,600+ unique topics).
Cost is dominated entirely by LLM classification; the embedding
bill is effectively free. The practical knobs if you want it even
cheaper: (1) cache hits are free, so re-running bellamem save on
the same transcript costs nothing — only new turns get classified;
(2) the daemon ticks every 5 minutes by default, but
--save-interval-minutes lets you stretch that arbitrarily, and
bellamem save is idempotent and can be called on demand (e.g.
from a git hook or manually) if you'd rather not run a daemon.
Requirements: Node 20+. Git (Bella scopes per-project state via the git repo root). No other system dependencies.
Seven ops cover the whole surface — ingest, three retrieval modes, audit, replay, and the web UI.
| Command | Question |
|---|---|
bellamem resume |
Where am I? What's been decided, what's open? |
bellamem save |
Ingest this session into the graph |
bellamem ask "X" |
Mass-ranked beliefs about X + 1-hop edge walk |
bellamem recall "X" |
Same as ask — the everyday retrieval alias |
bellamem why "X" |
What does X cause, what caused it, what does a fix have to respect |
bellamem audit |
5 health signals over the graph |
bellamem replay |
Chronological turn-by-turn view of the current session |
bellamem serve |
Localhost web UI with session trace scrubber |
bellamem daemon start |
Background service: save loop + web UI in one process |
# Ingest this project's most recent Claude Code session.
# Idempotent — re-runs only process new turns.
bellamem save
bellamem save --tail 50 # last 50 turns only
# Retrieve — same memory, three framings:
bellamem resume # the structured snapshot
bellamem ask "what did we decide about persistence"
bellamem why "retry-jitter fix" # cause chain + invariants + disputes
# Health:
bellamem audit
# Time:
bellamem replay # tail of the current session
bellamem replay --session 7e315796 --max-lines 30
# Web UI — foreground, ties up the terminal:
bellamem serve
# ...or the background daemon — one process serves the web UI
# AND runs a save loop every 5 minutes for every project it finds:
bellamem daemon start # detached, PID at ~/.config/bellamem/daemon.pid
bellamem daemon status # "running · pid 12345 · uptime 42s"
bellamem daemon logs --follow # tail -f the daemon log
bellamem daemon stopAll read-only except save. Write state is .graph/v02.json in the
project root; caches are in a scratch dir under $TMPDIR.
The daemon is the recommended "run up bellamem" path: start it once
at login (or from a shell rc line), and /bella in any Claude
Code session reads a graph the daemon is keeping fresh in the
background. The web UI at http://localhost:7878 discovers every
project on your machine that has a .graph/v02.json and presents
them on a single home page — cross-project dashboards come free.
The flow that lets you keep working past the context window without losing the thread is packaged into four slash commands.
Bella is built for — and tested daily against — Claude Code. Other coding agents (Codex, Cursor, Windsurf, OpenClaw) will need their own adapter; see #1 for the lifecycle hooks we're tracking.
bellamem install # writes ~/.claude/commands/bella.md/bella now works in every Claude Code project on your
machine. The template shells out to bellamem $ARGUMENTS, so whatever
bellamem is on PATH is what the slash command invokes.
| Command | What it does |
|---|---|
/bella or /bella resume |
Typed structural summary — invariants, open work, retracted approaches, recent decisions, disputes. Run at session start. |
/bella save |
Ingest the current session into the graph. Run before /clear or at end of day. |
/bella recall <topic> |
Mass-ranked beliefs about a topic, disputes included. Mid-session lookup. |
/bella why <topic> |
Pre-edit pack: invariants, disputes, causes, edge neighborhood. Run before a risky change. |
/bella replay / /bella audit |
Raw CLI output when you want to look at it directly. |
/bellamem save ← captures this session into the graph
/clear ← wipe the context window (Claude Code built-in)
/bellamem resume ← fresh assistant reconstructs where you were
On a well-tuned project, /bellamem resume comes back in ~30k
tokens and contains enough to pick up the next decision without
re-asking questions already answered.
Install bellamem-guard as a Claude Code PreToolUse hook and an
advisory pack (invariants + disputes + causes for the focus) is
injected automatically before every Edit / Write / MultiEdit
call — no manual invocation needed. The guard exit-2s when the edit
re-suggests a rejected approach (a ⊥ dispute), refusing the tool
call at the boundary.
Hook registration (once per project) in .claude/settings.json:
{
"hooks": {
"PreToolUse": [
{ "matcher": "Edit|Write|MultiEdit", "hooks": [{ "type": "command", "command": "bellamem-guard" }] }
]
}
}~/.claude/commands/
bellamem.md installed once (global slash command)
~/.config/bellamem/
.env user-level OPENAI_API_KEY (shared across projects)
<your-project>/
.claude/settings.json PreToolUse hook registration (optional)
.graph/
v02.json the typed belief graph (gitignored by default)
.env per-project override (optional)
$TMPDIR/bellamem-proto-tree/
proto-embed-cache.json classifier + embedding caches (shared across projects)
proto-llm-cache.json
.graph/ is gitignored by default.
Both compress a long session. The difference is load-bearing:
/compact |
Bella | |
|---|---|---|
| Output | One narrative summary (~2000 tokens) | Queryable belief graph (~3k per retrieval) |
| Shape | Prose | Beliefs + typed edges (→, ⊥, ⇒) + mass + voices + sources |
| Usage | Replaces history; summary becomes new context | Load on demand per turn; three retrieval modes |
| Preserves | Broad topics, major decisions, flow | Paraphrased decisions, rejected approaches, cause-effect chains, self-observations, line numbers |
| Loses | Identifiers, ⊥ corrections, causal structure | Tool outputs, file contents, conversational texture |
| Cross-session | None — dies with the session | Full — graph persists, next session inherits it |
On our 13-item bench, compact scored 8% LLM-judge; Bella's
expand scored 92%. Narrative summaries preserve themes;
structured retrieval preserves decisions. The two are complementary:
/compact keeps the feel inside one session; Bella keeps the
decisions across sessions.
Three live, clickable renders of Bella's own v0.2 concept graph —
real data, filtered to min_mass ≥ 0.7 so you see the ratified
structural spine instead of noise:
- 3D concept map — Three.js with UMAP × mass. Orbit, zoom, click any mesh.
- 2D force-directed (D3) — d3-force, draggable nodes.
- 2D force-directed (Cytoscape) — cytoscape + fcose.
Or visit the project page: https://immartian.github.io/bellamem/

Shape encodes class (hexagon/diamond/ellipse/cube), color encodes
nature (amber/blue/green), node size encodes mass, and typed edges
(→ support, ⇒ cause, … elaborate, ⊥ dispute) are the
structure that flat context can't preserve.
Latest measurement: benchmarks/v0.0.4rc1.md (2026-04-10, budget = 1200 tokens, LLM judge enabled, 13-item hand-labeled corpus, 1834-belief forest).
metric flat_tail compact rag_topk expand before_edit
----------------------------------------------------------------------------------
exact hit rate 15 % 0 % 15 % 69 % 46 %
embed hit rate 23 % 31 % 31 % 85 % 77 %
llm judge rate 0 % 8 % 31 % 92 % 69 %
avg tokens used 1200 602 1161 1143 964
flat_tail (0%) < compact (8%) < rag_topk (31%) < before_edit (69%) < expand (92%).
Headline story — compare to v0.0.2: as
the forest grew from the v0.0.2 dogfood snapshot to 1834 beliefs,
rag_topk collapsed from 85% → 31% LLM judge (cosine top-k pulls up
more plausible-looking-but-wrong neighbors in a larger forest), while
expand held at 92%. The gap from expand to the next-best contender
widened from 15pp to 61pp. Structured mass-weighted retrieval
scales with forest size; cosine top-k doesn't. The retrieval code
path (the v0.2 walker) is unchanged between v0.0.2
and v0.0.4rc1 — every delta is a property of forest growth, not
algorithm changes.
See benchmarks/README.md for the versioning convention and when to re-run.
The bench above answers "is expand accurate?" The next question
is "how many tokens does Bella actually save?" For that, the
docs/scenarios.md
harness measures real Claude Code session transcripts sampled from
15 different projects on a developer's machine — news monorepos,
IRB documents, refactoring sessions, agent prototypes, marketing
work — at a fixed expand budget of 1500 tokens.
| tokens | |
|---|---|
| raw conversation range | 274 → 132,399 |
| compression ratio range | 3.6× → 90× |
| median ratio | 17.6× |
Visually:

The pattern is unambiguous: expand honors whatever budget the
caller passes, regardless of how big the raw transcript got. The
horizontal line in the chart is the budget I picked for these
measurements (1500) — at budget=3000 every ratio would halve, at
budget=500 every ratio would triple. The actual claim is that the
ratio diverges with raw size at any budget you choose. Doubling raw
doesn't double expand; it doubles the ratio. The biggest sample (a
multi-day news monorepo session at 132k conversation tokens) hit 90×.
A second chart in the same doc shows the smaller-scale linear regime
where expand grows with raw — that's where the synthetic break-even
math gives the rule of thumb "don't bother with Bella for
conversations under ~200 tokens; the per-belief overhead dominates."
Above that, Bella pays off, and the longer the session, the more it
saves.
Sources are anonymised; only aggregate metrics are pinned.
Bella lives alongside the agent, not inside it. That boundary is load-bearing but not permanent — tracked as #1: Context lifecycle dependencies, blocked on upstream anthropics/claude-code#47023 (exposing compact/session lifecycle hooks). Today what we have is advisory:
- No direct context-window control. Bella can't swap active tokens, evict irrelevant context, or replace the window wholesale. The agent still controls what it attends to; Bella can only offer packs the agent can choose to read.
- /compact stays LLM-driven. Claude Code's native
/compactwrites a narrative summary via an LLM call. APreCompacthook that lets Bella substitute a graph-backed compaction would unlock most of the remaining wins — and that hook surface does not exist in Claude Code today. We can't intercept it from outside. - Save/clear/resume is a manual pattern. You run
/bellamem save→/clear→/bellamem resumeyourself. It works, but it's a human-in-the-loop ritual, not an autonomous context manager. - The edit guard is a tool-call boundary, not a semantic gate.
bellamem-guardinjects an advisory pack before every edit andexit-2s on a dispute re-suggestion, but it sees tool-call text, not model intent. An agent that ignores the advice can still try the edit; the block is at the boundary, not deeper in the model. - One adapter at a time. Claude Code works today. Codex and others need their own turn-pair reaction classifier and source stamper.
The common thread: every limitation above is about how much of the agent's context lifecycle we can observe and influence from outside. With deeper hooks — or a coding agent that exposed its context as a first-class API — a graph memory like Bella could drive the compaction cycle itself instead of being handed the leftovers. We expect the upside of real context-window control to be substantial. These aren't permanent trade-offs — they're tracked in #1, resolvable either upstream (via claude-code#47023) or downstream (transcript-watcher fallback). For now, the honest frame is: Bella is the memory layer; the agent is still the window manager.
v0.3.0-alpha — Node/TypeScript port, dogfooded on its own
construction. The rewrite session that produced this codebase was
ingested live into the graph it was building; every commit is
sourced in per-turn provenance. The trace view (localhost web UI)
lets you scrub through that session and watch concepts get born and
ratified turn by turn.
The Python v0.2 reference is frozen at tag v0.2.0-ref and has been
removed from master. The Node port produces byte-identical
.graph/v02.json, validated by a diff harness run against the live
567-concept graph on resume, audit, and replay.
- v0.3.0-alpha — TypeScript port, seven ops (resume/save/recall/why/ask/audit/replay),
bellamem servelocalhost web UI with session trace replay,bellamem installslash command writer, 51 vitest suites. - v0.3.1 (planned) — interactive ask in the web UI, 3D force graph (Three.js), progressive walker mode, guard daemon.
- v0.4 (planned) — log-odds decay on by default, schema evolution for multi-graph views across projects.
See CHANGELOG.md for details.
Everything lives in packages/bellamem/ (Node/TypeScript). Core is
schema.ts (Source/Concept/Edge + R1 mass) + graph.ts (container,
dedup, R5 sweep) + store.ts (atomic JSON). The read surfaces are
walker.ts (ask/recall/why), audit.ts, resume.ts, replay.ts.
Writes flow through ingest.ts (streaming jsonl → classifier →
applyClassification). The web UI is server.ts (Hono) + static
shells under web/.
Byte-compatible with the Python v0.2 reference — the v0.2.0-ref
tag holds the frozen Python implementation that the current port
was validated against.
Full layout and invariants: ARCHITECTURE.md.
The formal calculus — six rules, invariants, Bayesian grounding, domain-agnostic case studies — lives in its own repository under the Recursive Emergence org: Recursive-Emergence/bella.
- SPEC.md — the six rules, formal definitions
- VISION.md — theoretical grounding (Jaynes, Gödel, self-reference)
- EXAMPLES.md — case studies (H. pylori, continental drift, …)
- MEMORY.md — how BELLA maps to LLM agent memory
- replay/ — historical-event validation harness (Wirecard, Theranos, Wakefield, Hydroxychloroquine)
bellamem is the empirical tool that applies that calculus as
persistent memory for LLM coding agents.
The implementation spec — schema, R1 formula, classifier prompt
(verbatim), cache keys, audit thresholds — is
docs/rewrite/v0.2-spec.md. Any
future port must implement against that contract.
Short version:
cd packages/bellamem && npm install && npm test— 51 tests covering schema, graph, audit, walker, resume, replay, round-trip..graph/v02.jsonis frozen. Any change to the schema,PROMPT_VERSION,DEDUP_COSINE, R1 mass deltas, or audit thresholds needs to land alongside a migration plan.- Dogfood changes against bellamem's own graph before shipping.
Unit tests prove code runs;
bellamem resume --graph ./graph/v02.jsonbellamem serveprove the feature is useful.
- Commit messages lead with what changed, then a brief why.
Built with Claude Code. Bella is
primarily an AI-collaborative project. The
BELLA specification and the
Recursive Emergence framework
are Isaac Mao's independent research;
the Python and TypeScript implementations are heavily co-written with
Claude across long multi-month sessions. Commits made from inside
Claude Code carry the standard Co-Authored-By: Claude <noreply@anthropic.com> trailer.
Most distinctively, Bella dogfoods itself. Every design decision,
dispute, and causal chain from Bella's own development lives in Bella's
own belief graph — the same graph anyone else's Claude Code sessions
would write to. When a new session starts with /bellamem resume,
Claude Code is loading Bella's memory of what Bella already decided,
across hundreds of prior turns and dozens of prior sessions. The
recursive loop is the project's strongest field test: Bella and Claude
Code co-developed each other, and the graph is the record of that
collaboration.
AGPL-3.0-or-later. See LICENSE.